An Introduction to CI/CD on Microsoft Fabric

Context & Intro
In December 2024, I gave a lightning talk at the Dublin Fabric User Group providing a brief introduction to Continuous Integration and Continuous Deployment (CI/CD) on Microsoft Fabric. In researching the topic as well as various customer conversations, I’ve noticed that while the Microsoft documentation is quite detailed, especially for implementation steps, there wasn’t a single overview of the CI/CD options available.
CI/CD are fundamental practices in modern software development, designed to streamline the process of integrating code changes and deploying applications. By incorporating CI/CD, development teams can enhance efficiency, reduce errors, and improve the overall quality of software products. In this blog post, we explore working with branches and CI/CD capabilities in Microsoft Fabric.
Before getting into it, I’ll just mention that this is intended to be a very brief introduction to those unfamiliar with CI/CD on Fabric. Other blog posts do a great job of describing practical scenarios and technical details - here my intention is to set a foundation in about 1,000 words.
What and Why
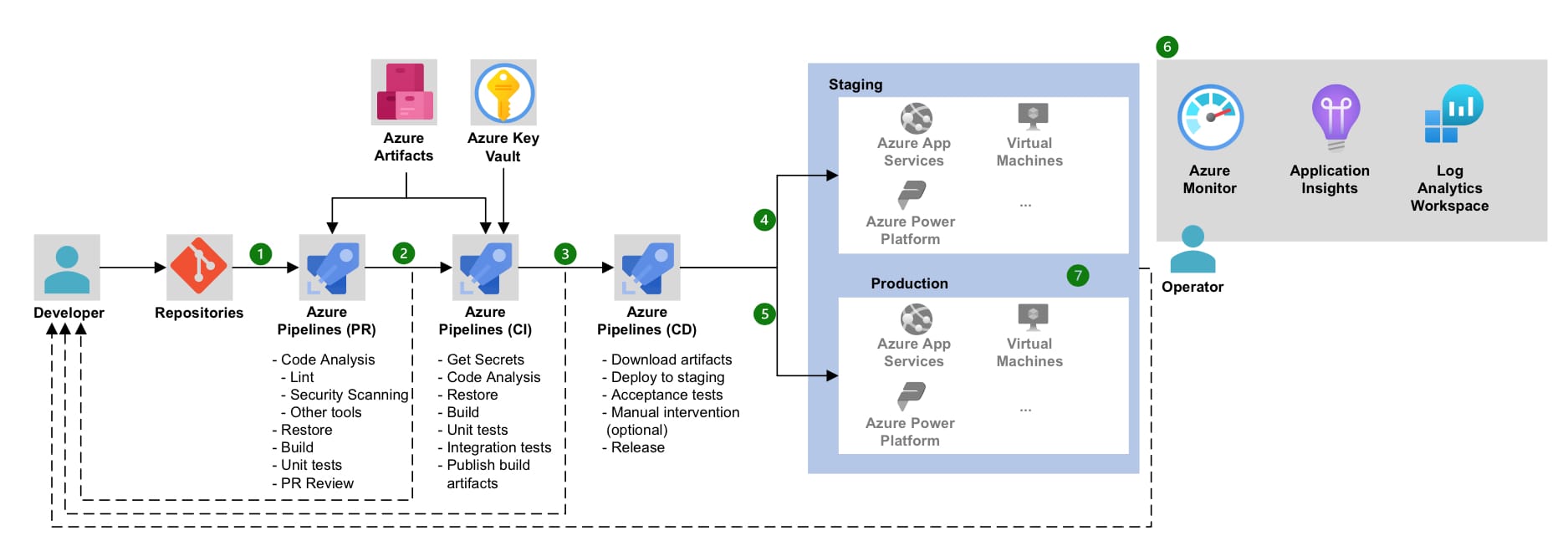
You will often see CI/CD referenced as a single concept, ultimately resulting in automated deployment of software products or applications, but each element is distinct. Continuous Integration (CI) and Continuous Deployment (CD), is a set of practices in software development aimed at ensuring that code changes are automatically tested and deployed to production. CI involves developers frequently integrating their code changes into a central repository, where automated builds and tests are run. CD extends this by automatically releasing validated changes to production, allowing for frequent and reliable updates. There are plenty of resources describing CI/CD (e.g. this from Atlassian) and the benefits. Without sharing details, some of these include; early bug detection, improved collaboration, faster development, easier rollback, and reduced manual effort.
Working with Branches
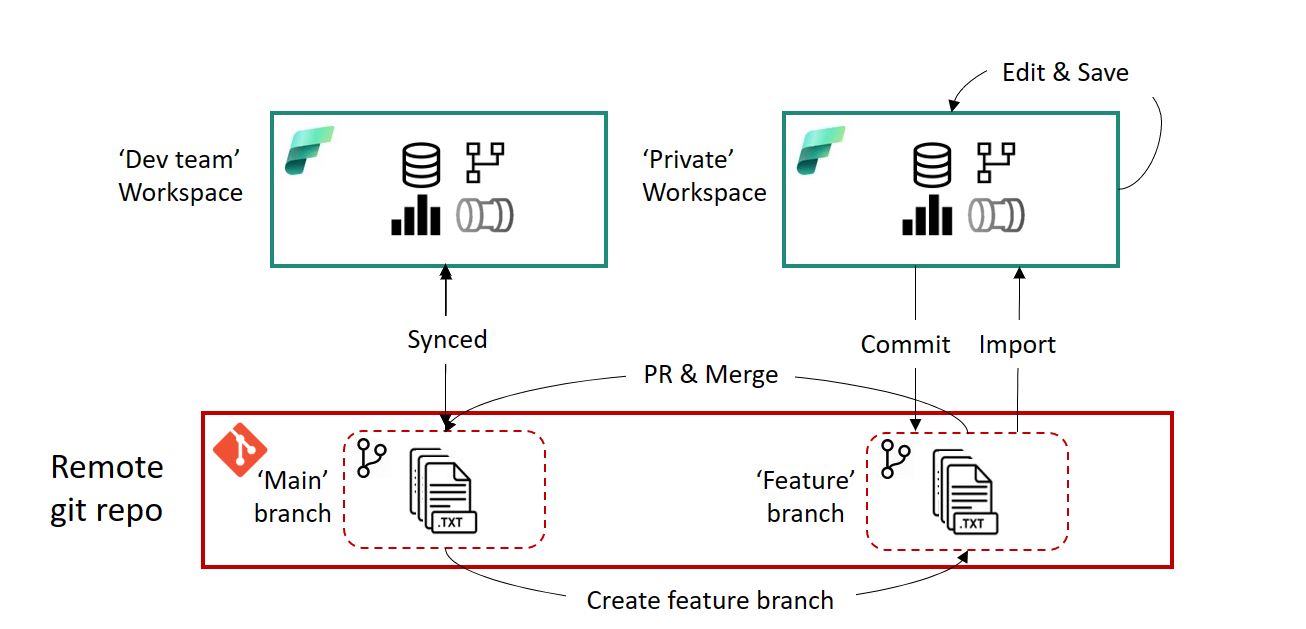
In Fabric, workspaces are your governance and development boundary, and your central location for storing source code (Azure DevOps, GitHub) is enabled through git integration. When you start looking to use Microsoft Fabric Git integration at scale you are going to be working with both branches and pull requests. Branches are an interesting concept in Git - a branch looks and feels like an entirely new copy of your work. They allow you to work with your code in a new area within the same Git repository, e.g. through the use of a feature branch which is a branch you work with short-term for a specific feature. Once finished you apply your changes back to the branch you were working on another branch.
Typically, you make changes in one branch and then merge those changes into another. These should not be confused with deployment environments. Where you deploy to various environments to perform various levels of testing before deploying to a production environment. In reality, it does not make a full copy of your work in a new branch. Instead, branches and changes are managed by Git. Anyway, there are a number of different ways you can manage branches including using client tools or workspaces (described here).
CI/CD Options in Fabric
For CI functionality, Fabric natively integrates with either Azure DevOps or GitHub.
As for CD, Microsoft has some guidance, and there are intricacies in how these are applied, but there are a few options here too; deployment pipelines, git integration, or REST APIs (CRUD).
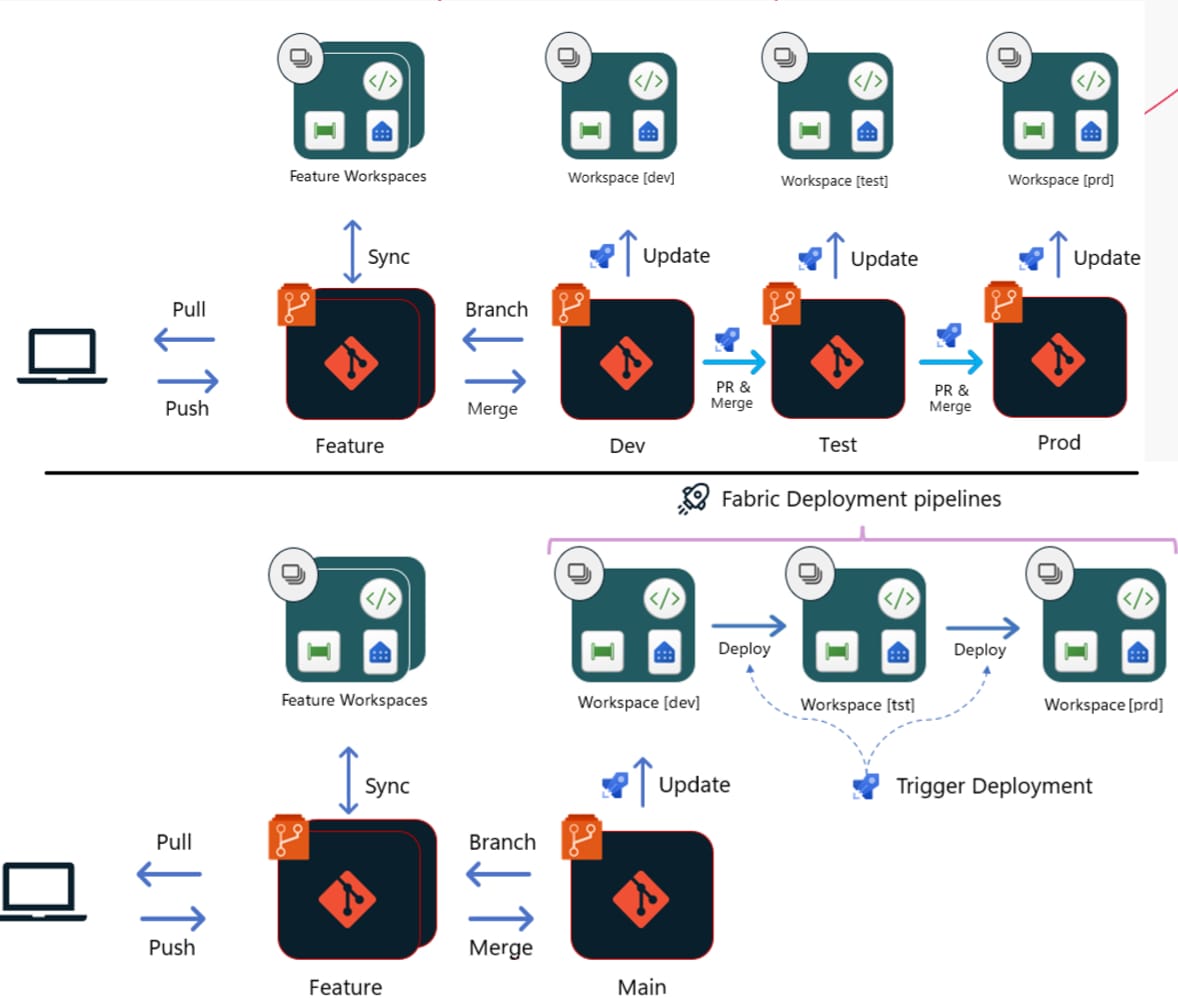
From what I’ve seen, the direction of travel is a preference for the bottom option, utilising deployment pipelines, but due to challenges with functionality until recently, most people using CI/CD on Fabric in anger are using some customized version of git integration - some examples I’ve seen show the most complex environments using native Git API integration, but this seems to be less common.
In reality, this all depends on your branching model (Trunk based, Gitflow) as well as requirements such as whether you want to trigger deployment from Fabric or Git.
State of Play
EDIT: In February 2025, Mathias Thierback shared an updated version of his CI/CD support matrix That supersedes the below. The remaining challenges and lessons learned are mostly still relevant, but please do visit here for the update.
First of all, shout out to Mathias Thierback who not only created a version of this including Terraform, but has been presenting on all things Fabric CI/CD over the last month. Additionally, I haven’t considered Airflow Jobs. As for those marked proceed with caution, I’ve explained why in the final section of the blog.

Lessons Learned & What’s Next
I’ve seen a number of challenges with CI/CD on Fabric. Most issues can be maneouvered around, utilising Metadata driven pipelines for example, but it’s worth mentioning. For example;
- Dataflows do not support deployment pipeline rules
- Notebooks don’t support parameters
- Where default lakehouses change across workspaces, the attachment doesn’t propagate
As for other lessons learned:
- The REST API offers most flexibility, but is the most complex to implement, whereas deployment pipelines offer the least flexibility but are the most straightforward to implement
- While there is support across a range of items, in my experience, notebooks really are the way to go for version control and CI/CD native integration to minimise potential issues
- REST API implementation is only possible for all items through users rather than Service Principals. This is being improved upon over the last couple of months but isolated to Lakehouses and Notebooks at the time of writing
- Unsurprisingly, good general CI/CD practices apply (e.g. early & often releases)
- Some limitations exist (e.g. CI/CD or workspace variables, pipeline parameters being passed to DFG2 or pipelines invoking dataflows not supported)
- Some specific guidance around ADO and GH e.g. regions and commit size are available on MS Learn. ADO recommended
- When you have a dataflow that contains semantic models that are configured with incremental refresh, the refresh policy isn't copied or overwritten during deployment. After deploying a dataflow that includes a semantic model with incremental refresh to a stage that doesn't include this dataflow, if you have a refresh policy you'll need to reconfigure it in the target stage
- This blog hasn’t touched upon two important areas for implementation including naming conventions (this post from Kevin Chant is great) and workspace structure (many posts online, but I’ve also written this blog)