AWS Data Governance - DataZone Preview Thoughts

Amazon DataZone is an AWS data governance solution announced at 2022 (November) re invent and currently in preview. Focused on democratisation of data by domain and exploring pub-sub self-service access to data. In addition to data access, it covers data catalog, business glossary, and metadata capture functionality. It’s worth noting that the positioning of DataZone is closely linked to some key areas, including, data mesh architecture.
A couple of things to point out about the preview are that it's currently free while in preview, the preview is limited to Ireland, US East, and US West regions, and as per the banner of the UI, it's recommended to avoid using for production purposes while in preview.
Why I’m Interested
Data management and governance is something that has been vital to success of data teams for as long as I have been working in the field (and much longer), but I believe that it’s beginning to to have a renewed focus in the previous couple of years. There are a number of reasons for this that I won’t be diving into here, such as the simple fact that many key pillars in technology and data tend to go through cycles of perceived importance. That said, I feel it worth mentioning that the move to cloud, huge increase in production and availability of data, and treatment of data as a product do make the value proposition of a service like AWS DataZone potentially massive.
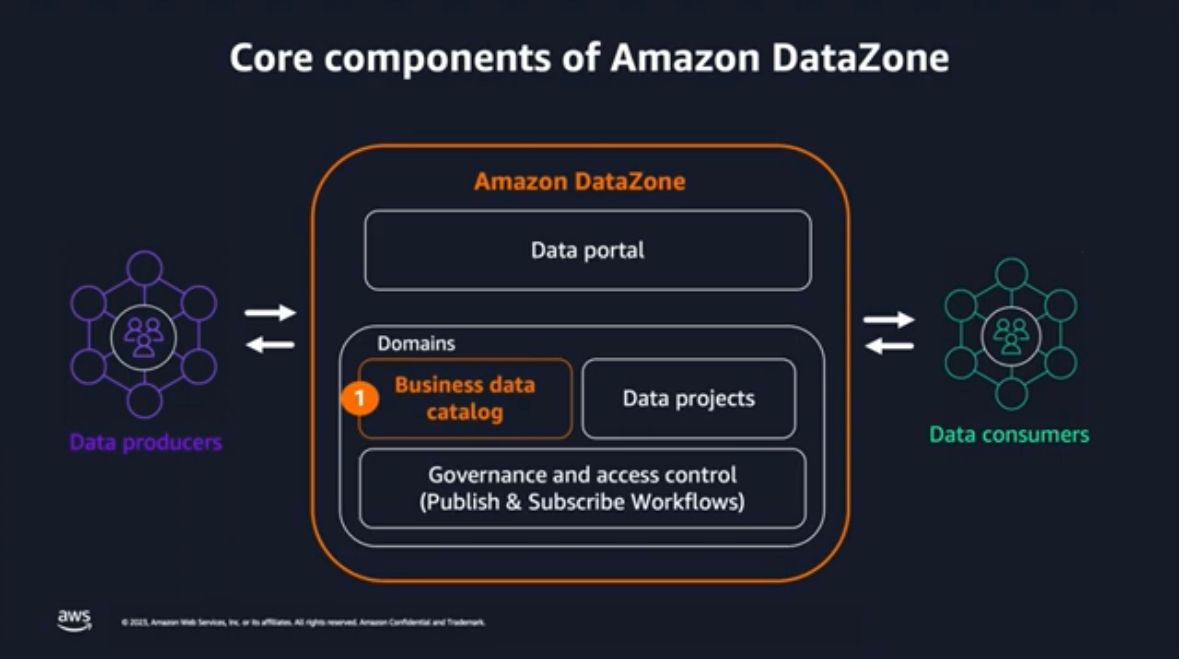
Key Enablers
I’m keen to get to my experience with the DataZone preview as soon as possible, but I think there are a couple of key things worth calling out in terms of key enablers or success factors - i.e. the things that may maximise the value of a DataZone deployment, or things that I think might result in challenges if you compare your experience to the slick tech demos seen online.
- Data stewards & Product owners - roles and responsibilities for self-service
- Understanding of existing data / domain structure - it’s important to consider how things should be structured for ease of management and use
- Maturity of datasets being published - to maximise value of AWS DataZone, the data must be usable and of high quality for consumers
Cost
DataZone is free for 3 months of use during preview, with some reasonable limits described in the pricing, so I think it’s a great opportunity to go and try using the service. After that, there is both a per month per user cost ($7.20-9USD) and a small cost for storing metadata. I’m unsure what the metadata cost will look like in real terms for large deployments, but it seems as though most of the cost will be on a per user basis.
Experience
I have seen some demos of DataZone where a series of steps were conducted to create data in Athena and bring in as net-new. I wanted to try pulling in already existing data to see what the process looked like as I imagine most deployments I would be likely to see will fit this use case. As it has been a few months since I’ve seen any demos or docs, I also wanted to try to go through the process as a completely new user to get a feel for what the learning curve would be like. Fortunately, I had some data from Kaggle (formula one dataset) in S3 already, so the only pre-requisite steps I conducted were to set up a Glue crawler for that s3 data to a new database.
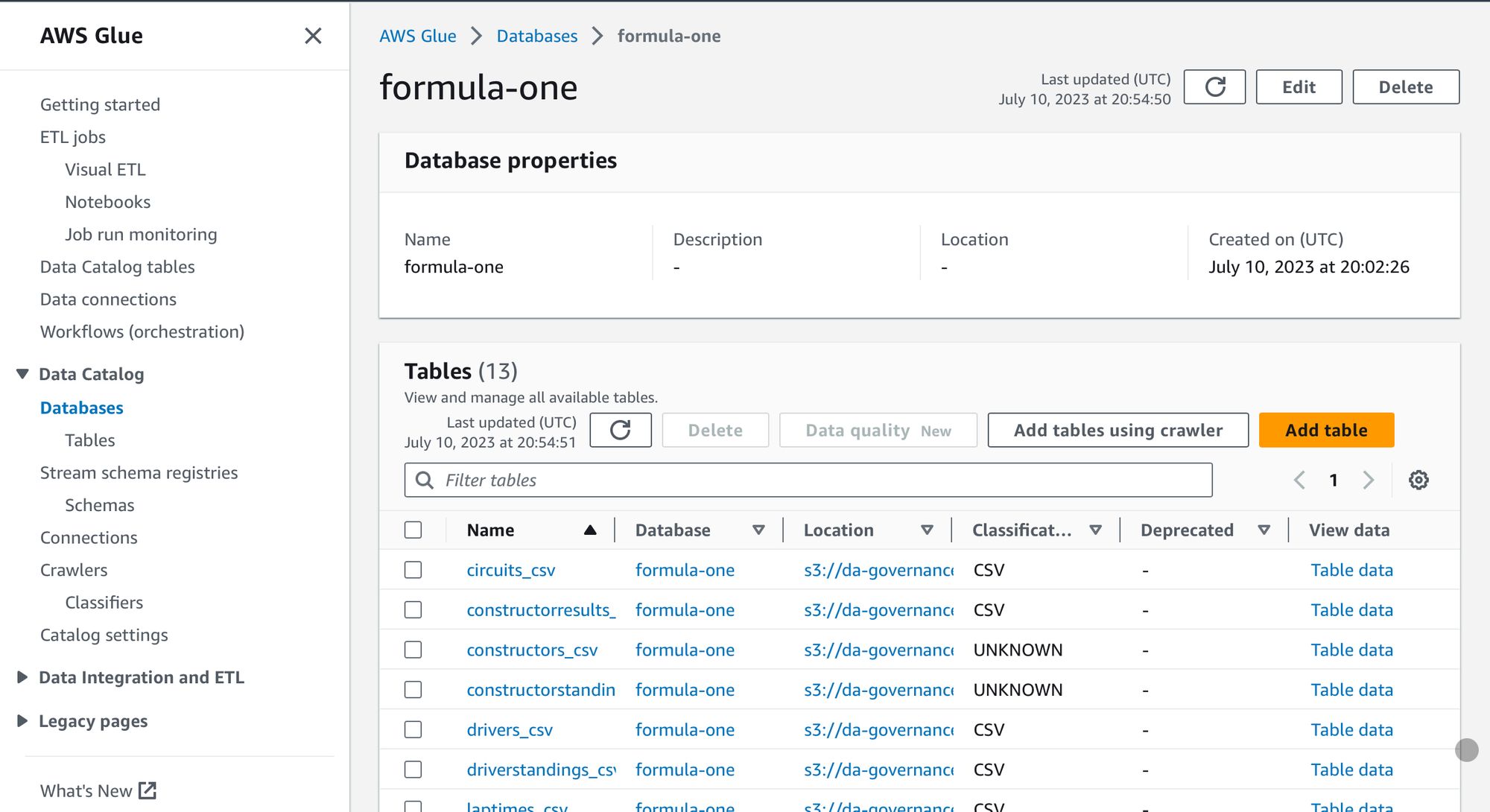
The creation of a domain, was fairly straightforward and the same can be said for creating DataZone projects, but this was where I felt I hit my first stumbling block as I couldn’t see any option to create the project linked to an existing Glue DB. I tried going back to the AWS console and adding my existing Glue DB as a data source, and voila, I could use an existing DB within the publisher project.
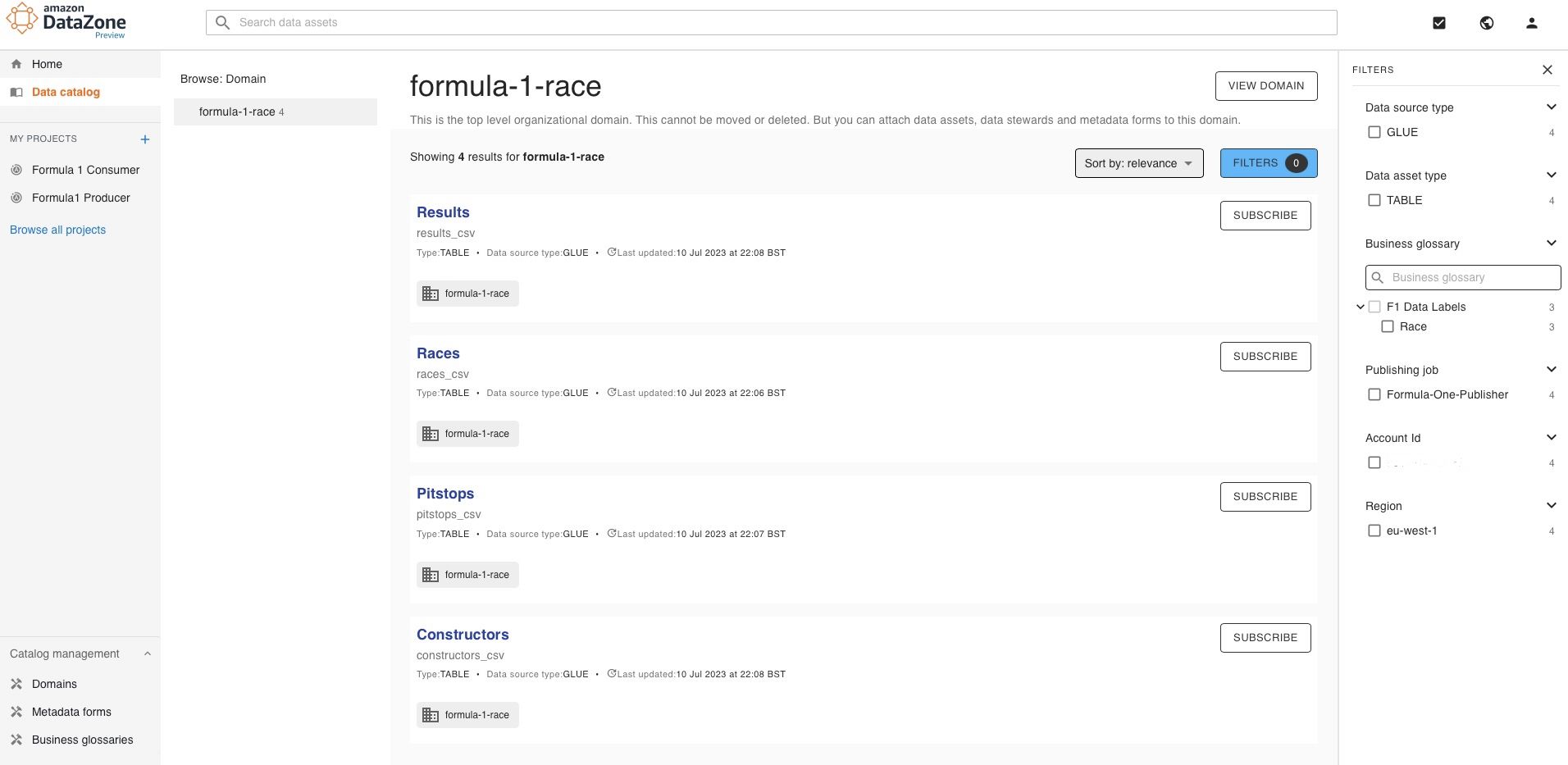
After running the crawler, publishing it to DataZone and making it active was really simple. I also liked that I had the option to either automatically publish as active, or draft (e.g. to remove table prefixes or similar) then active.
I then went through a couple of steps to create business glossary terms and metadata forms. Again, the creation was self explanatory, as was adding links to existing published data. The only challenge here is that it feels as though it would be quite manual to set up for a large data estate. It’s something I could see being improved over time such as adding a glossary term for “pit stop” to any data set with that in the title or columns.
After doing all of this setup, creating the subscription elements didn’t take long, there was just one added step where the access wasn’t granted after subscription approval. The issue was related to Lakeformation permissions and DataZone was really clear in sharing what needed to be granted, but in combination with AWS documentation, this is easily resolved. I followed the steps to add myself as datalake admin, remove the allowed principals (link, point 1), and grant specific access to the S3 location, Glue database, and tables (via lakeformation UI), re linked in the DataZone UI, and that was all the setup done. I even tested with an additional IAM user to see what it might look like for non-admins and I felt this was all quite seamless.
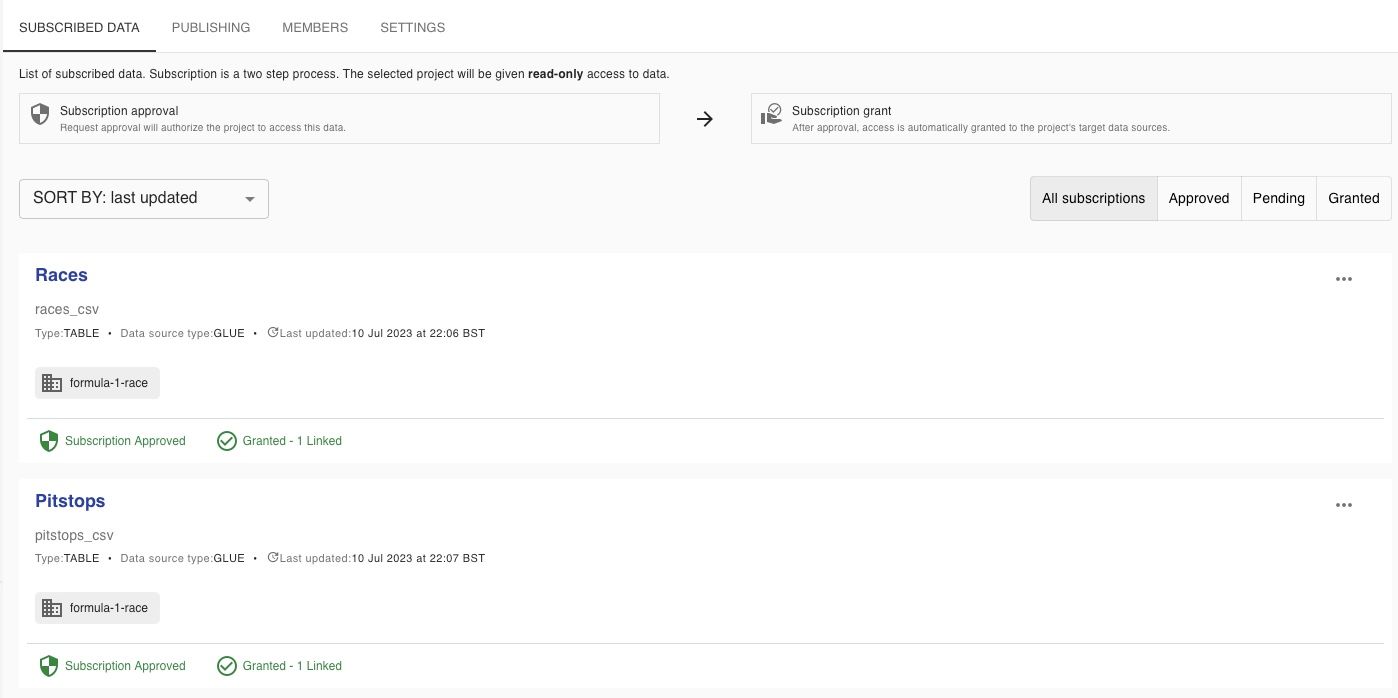
It may have taken a little longer first time round, but I think beginning the setup to end user querying the published data in Athena took around an hour. All-in-all, it felt like a brilliant experience.
Pros:
- AWS-native solution for data governance meaning seamless AWS integration
- Very user-friendly
- Business glossary, and the fact that search and filtering includes business glossary rather than just data assets
- Straightforward access management
- Can see benefit at large scale or multiple domains and data mesh environments where ownership and stewardship is democratised, but also in centralised data teams / functions with a broader group of users / consumers
Cons:
- Data Lineage not a key feature / use case
- Each data asset has to be subscribed to individually where the option to multi select could be helpful. The same applies to revoking subscriptions and deleting published assets
- A couple of specific issues in UI navigation - “open data portal” link didn’t seem to work on first click every time, query data (Athena) not working on iPad but did in safari on MacBook. This can be expected in preview, and didn't effect the overall experience
Future Considerations:
- Currently, notifications of subscription requests only appear in the DataZone portal. It would be cool to see email or text notifications (e.g. via SNS) so it's not reliant on admins or data stewards being in the data portal for visibility
- Data assets are limited to datasets - I would love to see this extended, for example, to include QuickSight dashboards
- It would be nice to see future identification of some business glossary term links automatically / dynamically
The big question - would I recommend it?
I think the short answer here is yes. There are a few things I’d like to dig deeper into including cross-account data sharing, integration with partner solutions (sales force, service now), what the workflow looks like for updating data assets from source, and learning the common pitfalls as with any new tool (e.g. don’t delete the glue tables before unsubscribing consumer jobs), but I think the potential for DataZone is huge, and it’s a large step in the right direction in AWS-native services supporting data management and governance. I’m really excited to see how DataZone develops going forward.