Fabric In Review: Thoughts 18 Months Later

Context & Intro
In the ever-evolving landscape of data analytics, Microsoft Fabric has emerged as a significant player, aiming to unify Azure Data Services to a single SaaS offering. This blog post reviews Fabric's journey, its unique selling points, areas for growth, and reflections on my experience. I’ve tried to keep thoughts relatively high level purely because delving in to all the good and bad things at a level of depth would create much larger lists.
Fabric’s Journey
Fabric's journey began in 2023 when, after a brief private preview, it was enabled in public preview for all tenants (May 2023), before its release to general availability in November 2023.
Microsoft also introduced the DP-600 and DP-700 or Analytics Engineer and Data Engineer certifications for Fabric, with DP-600 becoming Microsoft’s fastest-growing certification.
As of October 2024, Fabric touted over 14,000 customers (paying / non-trial) and over 17,000 individuals DP-600 certified. There has also been a significant investment in product development including Copilot integration, Real Time Intelligence, SQL Databases, industry-specific solutions (e.g. for manufacturing, healthcare, and ESG), and much needed improvement on functionality such as the eventual addition of Gen2 Dataflows CI/CD integration.
Fabric’s Unique Selling Points
- OneLake: provides a single data foundation with one copy of data accessible across all services. This also enables things like OneLake Data Catalog, Direct Lake Semantic Models, and the One Lake explorer for easily accessing Fabric assets you have access to
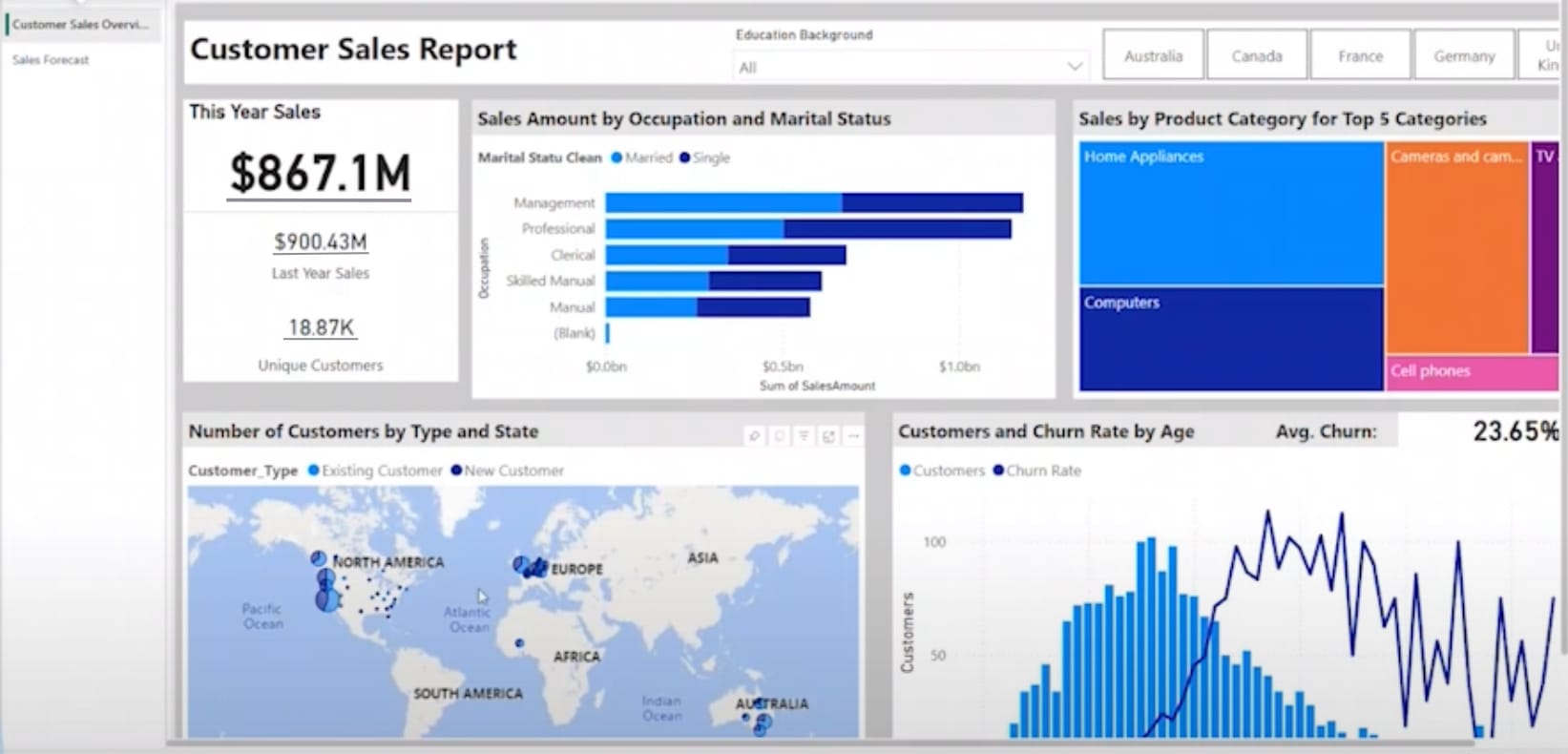
- AI Integration: Fabric’s ability to easily access AI experiences (model deployment, AI Skills) and Copilot to accelerate insights and development. For example, this can simplify and streamline the process of deploying an ML model and surfacing the output via Power BI (as captured by the predicted churn rate in the example report above). This really applies to the broad range of services (or “experiences”) but I think the combination of data engineering, analytics, and science through one interface is excellent
- Minimising friction / barrier to entry: Fabric offers a familiar and intuitive experience for users, especially those coming from Power BI. As a Microsoft SaaS solution, being built around M365 makes user access straightforward, the range of pre-built connectors and other functionality, and being able to combine pro and low code solutions as well as run a variety of workloads from one place can all contribute to a reduced time to value. I think it’s noticeable when you work through your first few development experiences just how quickly you can get something prototyped - for those who are new, I highly recommend both Microsoft’s end to end scenarios and Alex Power’s Data Factory In A Day repo.
- Governance and Security: It felt like a cop-out titling something “not just ETL and analytics” so I’ve tried to be more concise - many platforms require integration with other toolsets for item level lineage and orchestration, or cataloging data. Fabric enables governance functionality out of the box including monitoring through the capacity metrics app, workspace and item lineage, and row and object level security
Areas for Growth
- Feature Lifecycle: While there’s been an incredible amount of progress made in terms of features released, and the Fabric release plan can be a help, there is still a remarkable number of features that are “preview” with no real idea what that means in terms of maturity (varies feature to feature). There are even some examples where there are two versions of the same feature such as “invoke pipeline” activity having a legacy and preview option, or Dataflow Gen2 having a GA version and preview (supporting CI/CD) version. For those working with new Fabric items, you will run into hiccups occasionally, but this is also tricky for new users to navigate. It would be great to see this improve, especially around core workloads
- Capacity Management: When you purchase a capacity and attach workspaces to it, all workloads have been treated equally over the last 18 months. This causes challenges with a lack of functionality for queueing, workload management, and capacity consumption that need addressing. Currently, the main way to do this is with separate capacities
- Cost Estimation: Estimating costs for capacity planning remains difficult. There is a calculator available in preview that I’ve had good experiences with, but for new or prospective customers, this is still a challenge
- Solution or Deployment Best Practices: First, I appreciate that it’s not a vendor’s responsibility to define best practices, but I’ve found that the documentation can vary in terms of value. Some great articles are out there and easy to find like learning modules, demos, and specific development guidance (e.g. Python) as well as phenomenal community resources, but high level things supporting customer deployment like capacity management best practices, migration from SSAS multi-dimensional cubes, and moving from Power BI (e.g. gen2 dataflow performance) aren’t easy to navigate, and even at a lower level you can see examples such as MS documents like this one making users assume V-Order being enabled all the time would be the right thing to do. Sometimes this can necessitate the development of workarounds for specific challenges, custom solutions, or confusion related to making core decisions like how to manage CI/CD
My Experience
The above is a great snapshot of some individual experiences and the current online discourse around Fabric being truly “production ready” but over the last number of months I’ve struggled with some sweeping statements, both good and bad, around things Fabric can or cannot be used for. Of course, with data platforms, there are tradeoffs no matter what tooling you choose, and scenarios where certain tools are more closely aligned to requirements, but I wanted to add some generalised customer examples and patterns I’ve seen and why Fabric was viewed to be a good fit. There are some more examples I could add, but at that point it would be a blog on it’s own, so here are 4 examples, all of which I’ve seen first-hand:
- Existing Microsoft (M365 & Azure) customers: I’ve separated this from “existing Power BI customers” for two reasons; first, I’ve seen organisations utilising Azure but not Power BI for their core BI workloads (e.g. where Qlik or Tableau have been used historically), and, second, is that drivers for implementation in this example differ compared to extending Power BI functionality (e.g. strategic modernisation, migrating from a multi-vendor environment, or adding Fabric as the single pane of glass across multiple data or cloud providers). For larger customers already in the Microsoft ecosystem, the tight integration with M365, ability to reuse existing infrastructure config (networking, landing zone), and being able to work with an existing vendor have all been seen as positive, as are ability to utilise Copilot and shortcuts supporting landing data cross-cloud. A couple of lessons learned are that, especially for the managed self-service pattern, it’s worthwhile considering implementing both Fabric-capacity-backed and Pro workspaces, and utilising pro-code experiences where possible (appreciating availability of skills and personal preferences) will offer benefits around capacity consumption
- Small(er) Businesses - I know organisation size is all relative, but here I specifically mean where data volumes aren’t in the Terabytes and the data team is usually made up of people wearing multiple hats (engineering, analytics, architecture). SQLGene has posted their thoughts here, but my short summary here is that Fabric does offer a very easy way to just jump in, and can be a one stop shop for data workloads as well as offering flex in generally having multiple ways to get the job done as well as minimising the overall solution components to manage
- Power BI customers looking to “do more,” without well established ETL capabilities, OR those migrating on-premises SQL (and SSIS) workloads - I’ve worked with a number of Power BI customers where there is already a good understanding of workspace admin and governance, the web UI, Microsoft SQL. This can make Fabric feel like an extension of something that’s already known and improve adoption speed. It’s common for many of these customers to also be looking to move some on-premises SQL workloads to the cloud, and being able to re-use data gateway connections is a plus. Some customers I’ve worked with have been able to migrate historic ETL processes by utilising copy jobs or dataflows for extracting and loading to Fabric before migrating SSIS stored procedures and creating semantic models rapidly (hours / days)
- Greenfield scenarios - I think Fabric has a high value proposition in a number of scenarios, but I think it’s especially easy to understand this when you’re starting net-new. Alternate tech stacks may do specific elements really well, but you would need to stitch together more individual components, billing models, authentication methods etc. to meet engineering, analytics, science, architecture, and governance requirements. A good example was a project whereby there was a known requirement for analytics / reporting, as well as a data warehouse as well as minimal resources to support from central IT so being able to utilise a SaaS product that could meet functionality as well minimise infrastructure and operational support from IT was a big plus
Conclusion
Microsoft Fabric has been a fascinating addition to both Microsoft services and the data & AI technical landscape, but addressing some areas outlined above and core challenges in line with customer feedback will be crucial for its continued success. I would also highlight that the amount of development over the last 18 months and pace of updates has been impressive, so all of the above has to be taken in context of a technology offering that is still early in its product lifecycle and has massive further potential - in my opinion, Power BI was less impressive at a similar point.