Metadata Driven Fabric Pipelines (2 of 2) - Dynamic Pipelines & Deployment

So, you've created a wonderful pipeline in Microsoft Fabric, but everything is point-and-click or copy-and-paste when changes need made either within a single environment or after deployment to a new workspace. For anyone who wants to re-create what I'm working on up until this point, that is a sample lakehouse, warehouse, basic ingestion pipeline and dataflow, and a deployment pipeline, please see part 1 in my last post. There's some more information there around an introduction and context, but the aim of this blog is to focus on providing information around driving a Fabric pipeline through metadata, parameters, and variables, so let's get stuck in.
Creating the metadata
Our first step is to create the warehouse table we will use to drive the dynamic content used later. Before moving on to the actual table creation, it's worth opening VSCode notepad, OneNote, or wherever you store text for using later, and grab your warehouse ID and SQL connection string. For the warehouse ID, open the warehouse from you workspace and copy the text after '/warehouses' and up to, but excluding '?experience' in the url (in the red box in the image below), and for the connection string, you need to open the warehouse settings then navigate to SQL endpoint and copy the connection string. Do this for both the dev and test environments. We also want to grab a couple of other bits of information while we're here; the text after groups but before warehouses (in the blue box from the image below) is your workspace id, and lakehouse id follows the same process as warehouse id but you should see '/lakehouses/' in the URL.

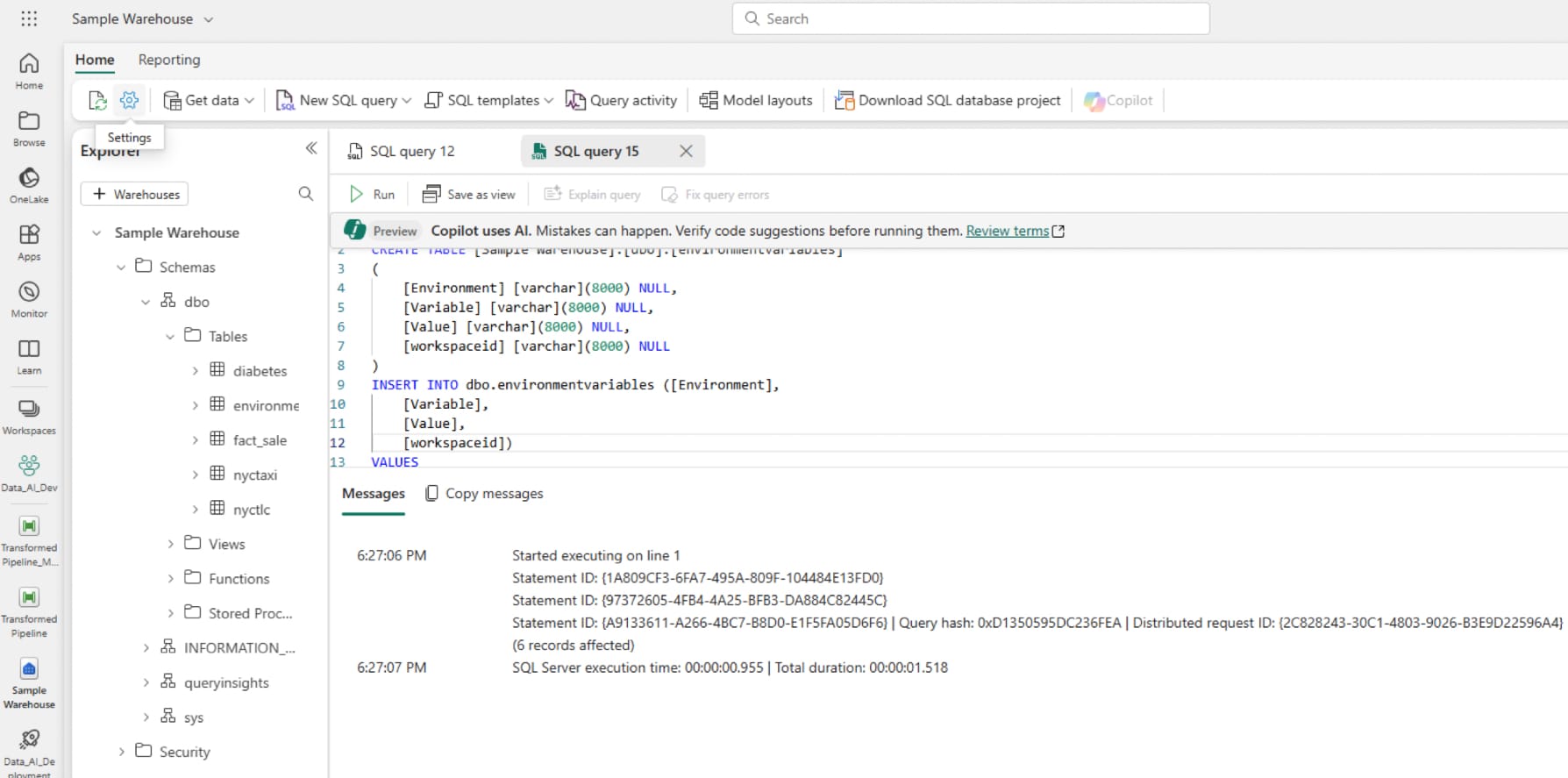
Use these values to replace the 'mywarehouse...', 'workspace_id,' and 'warehouse_id' variables in the below SQL query and run it in the sample warehouse in the dev environment. I've taken the approach of only creating this table once and pointing all environments back to the table in dev, but this could just as easily be run in each environment.
DROP TABLE IF EXISTS [Sample Warehouse].[dbo].[environmentvariables]
CREATE TABLE [Sample Warehouse].[dbo].[environmentvariables]
(
[Environment] [varchar](8000) NULL,
[Variable] [varchar](8000) NULL,
[Value] [varchar](8000) NULL,
[workspaceid] [varchar](8000) NULL
)
INSERT INTO dbo.environmentvariables ([Environment],
[Variable],
[Value],
[workspaceid])
VALUES
('Dev', 'sqlstring', 'mywarehousex.datawarehouse.fabric.microsoft.com', 'workspace_id_a'),
('Dev', 'warehouseid', 'warehouse_id_x', 'workspace_id_a'),
('Dev', 'lakehouseid', 'lakehouse_id_x', 'workspace_id_a'),
('Test', 'sqlstring', 'mywarehousey.datawarehouse.fabric.microsoft.com', 'workspace_id_b'),
('Test', 'warehouseid', 'warehouse_id_y', 'workspace_id_b'),
('Test', 'lakehouseid', 'lakehouse_id_x', 'workspace_id_b'),
('Prod', 'sqlstring', 'mywarehousez.datawarehouse.fabric.microsoft.com', 'workspace_id_c'),
('Prod', 'warehouseid', 'warehouse_id_z', 'workspace_id_c'),
('Prod', 'lakehouseid', 'lakehouse_id_z', 'workspace_id_c');
Adjust the Pipeline
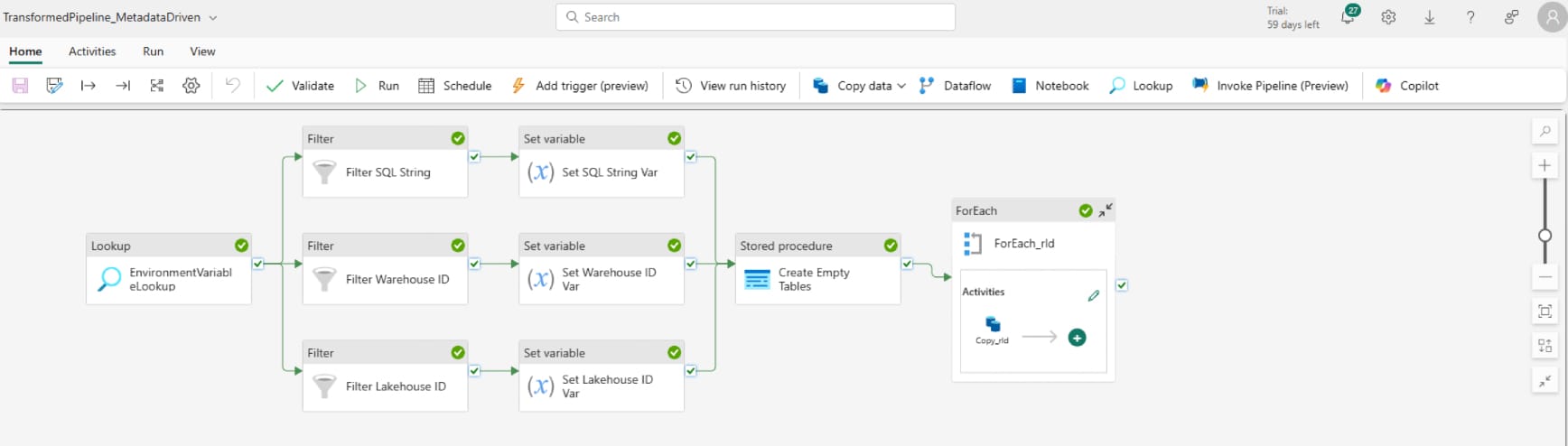
Now we have things set up, there are some additions to be made to the transformation pipeline, so navigate to your pipeline (starting point below).
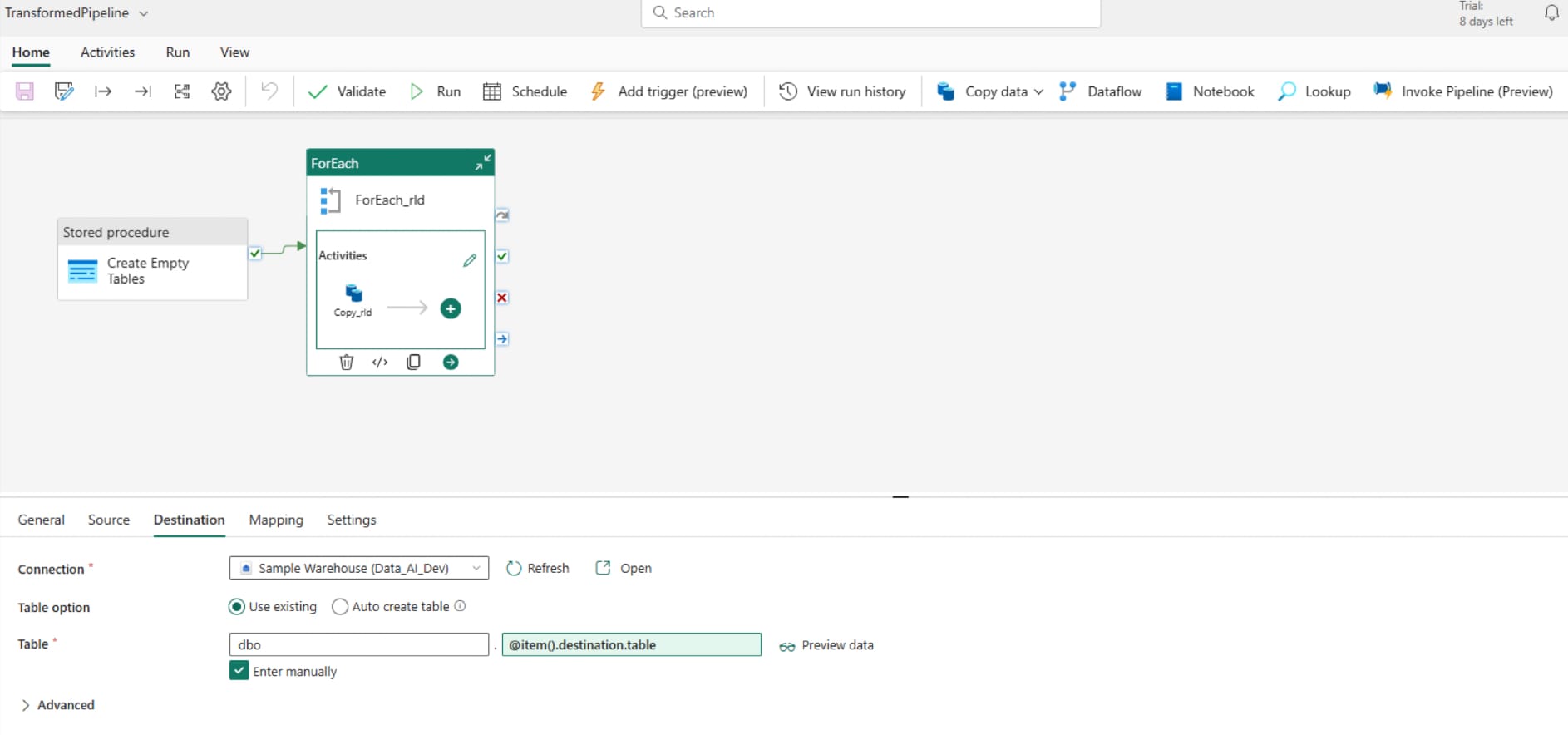
Start by adding the relevant variables that we will populate from the environment variables. Here I've labelled them as 'sqlstring', 'warehouseid' and 'lakehouseid':
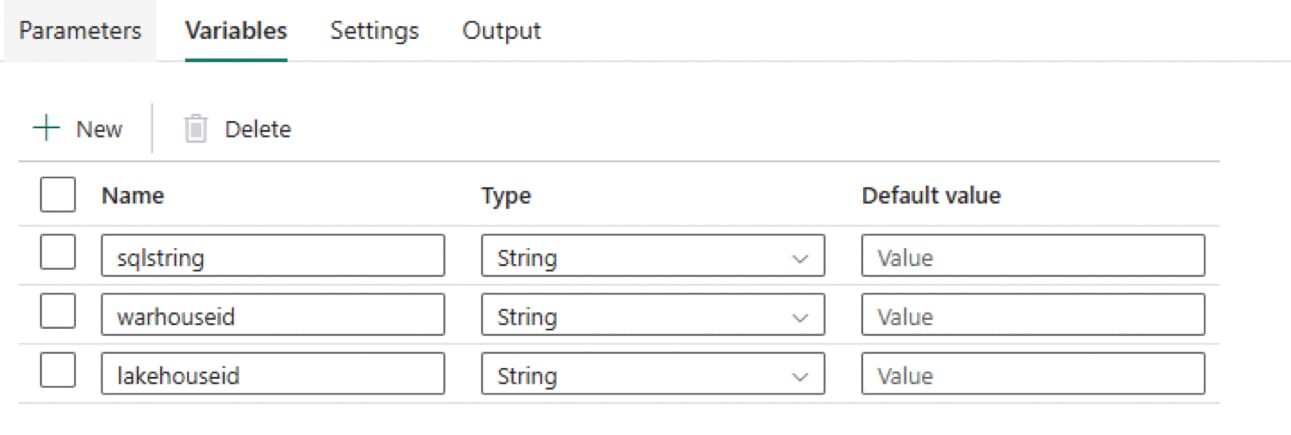
Then add a lookup activity and configure it to connect to the sample warehouse. Tick 'Enter manually' for the table details and enter dbo.environmentvariables or whatever you named the table from the above sql query if you changed it. Make sure to UNTICK the 'First row only' setting
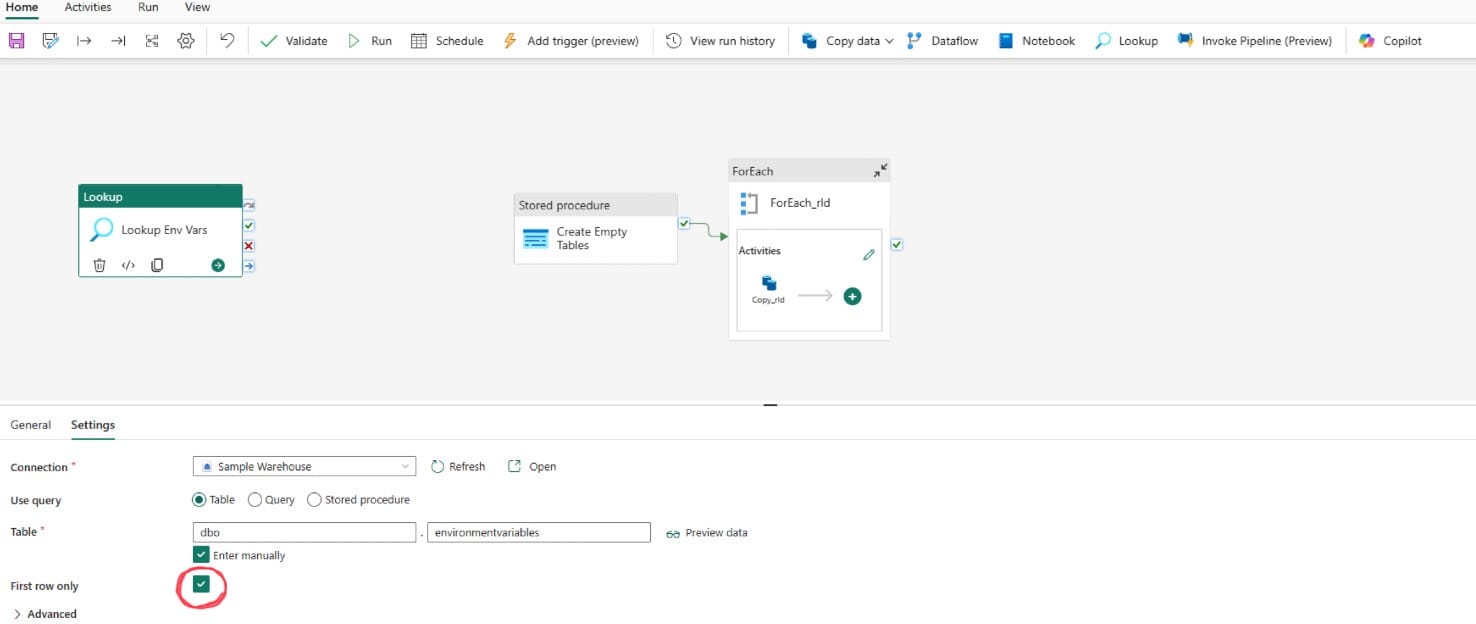
At this point, the activity would simply read the environment variables table. The next step is to create to activity streams, each filtering to a single entry in the table to collect and set one variable (the sql string then warehouse id). First, add a filter activity, connect the lookup activity, on success, to the filter activity, and configure as below. Please note, that the two text entries in quotes need to be configured to the title of the lookup step ('EnvironmentVariableLookup' for me) and the variable name you've given the sql string in the original query ('sqlstring' for me):
- Items - @activity('EnvironmentVariableLookup').output.value
- Condition - @and(equals(item().workspaceid,pipeline().DataFactory), equals(item().Variable,'sqlstring'))
Next, add a 'set variable' activity, connect (on success) the filter activity to the set variable activity, and configure the settings as below:
- Name - sqlstring
- Value - @activity('Filter SQL String').output.value[0].Value
This is taking the array value from the column 'Value' of our environment variables filtered table and assigning it to the sqlstring variable.
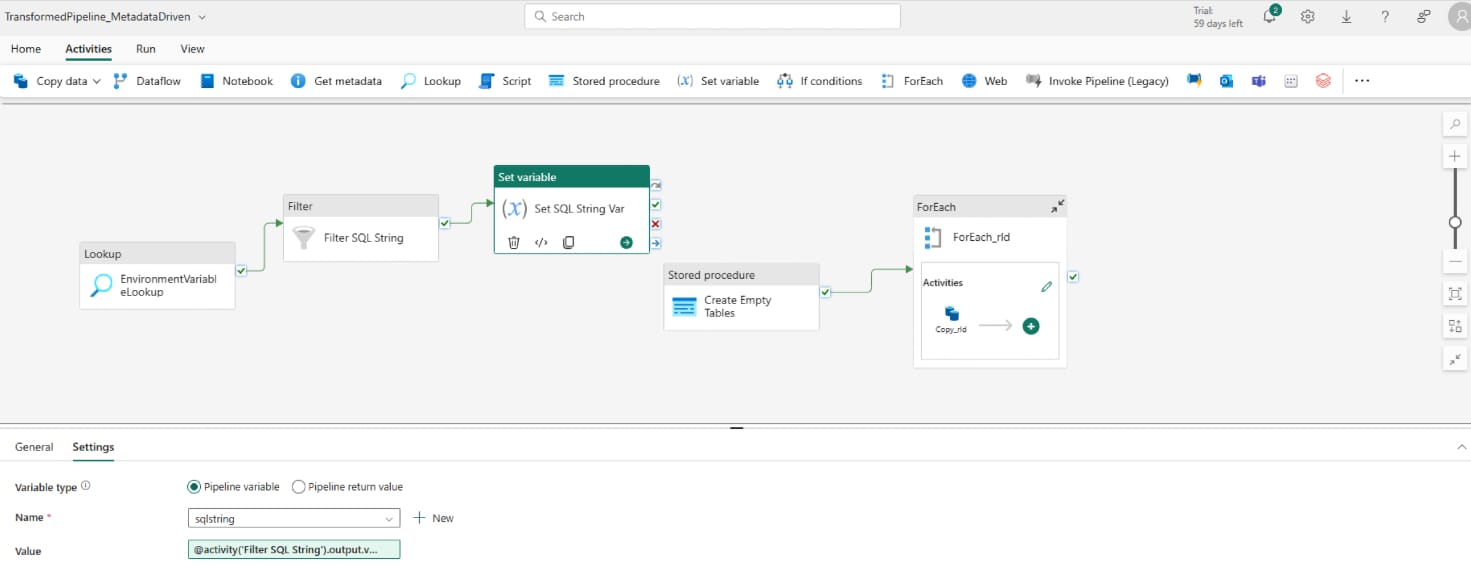
This needs to be repeated for the warehouse ID and lakehouse ID. You'll notice below that it's only the text in the variable value calling back to the activity in set variable and condition to select the right variable in filter that change
| Activity | Setting | Value |
|---|---|---|
| Warehouse ID Filter | Items | @activity('EnvironmentVariableLookup').output.value |
| Warehouse ID Filter | Condition | @and(equals(item().workspaceid,pipeline().DataFactory), equals(item().Variable,'warehouseid')) |
| Warehouse ID Set Variable | Name | warehouseid |
| Warehouse ID Set Variable | Value | @activity('Filter Warehouse ID').output.value[0].Value |
| Lakehouse ID Filter | Items | @activity('EnvironmentVariableLookup').output.value |
| Lakehouse ID Filter | Condition | @and(equals(item().workspaceid,pipeline().DataFactory), equals(item().Variable,'lakehouseid')) |
| Lakehouse ID Set Variable | Name | lakehouseid |
| Lakehouse ID Set Variable | Value | @activity('Filter Lakehouse ID').output.value[0].Value |
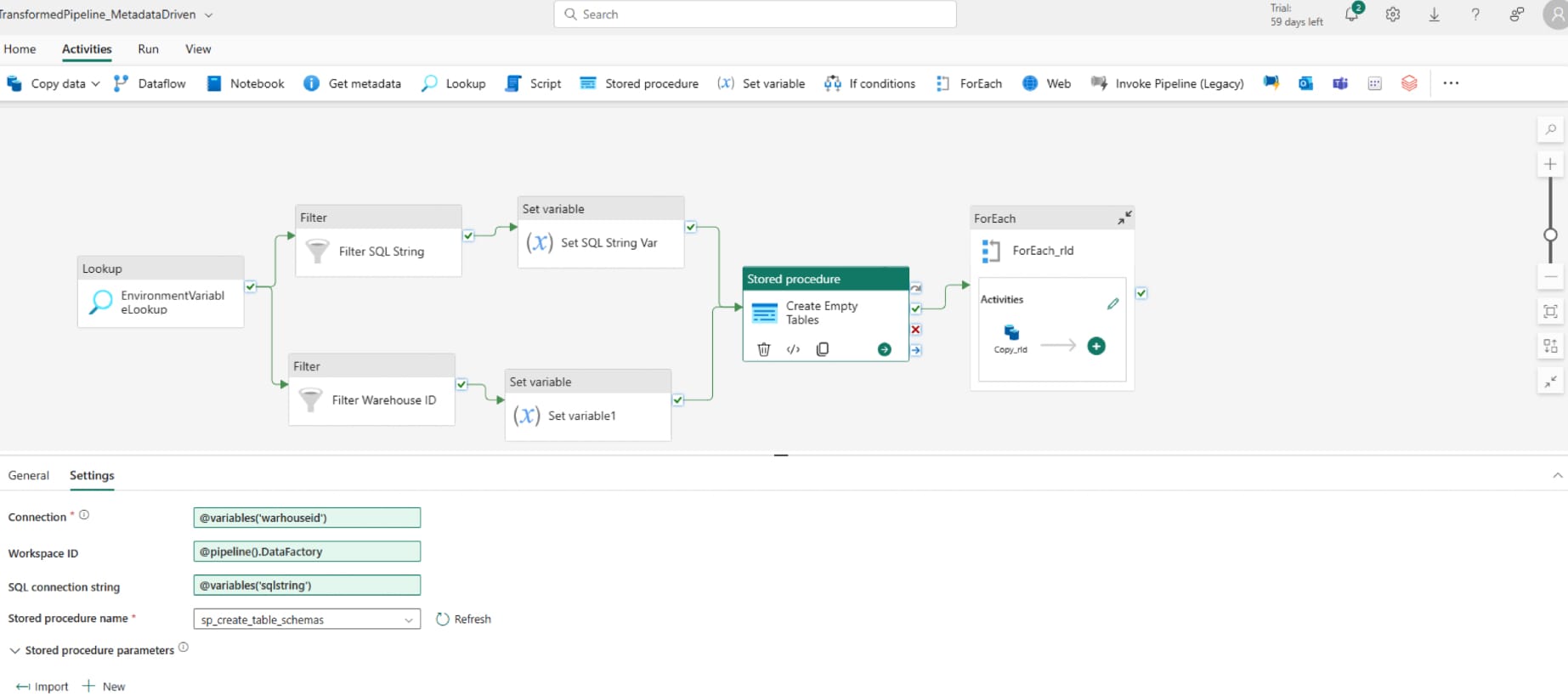
After connecting these to the stored procedure, now we need to adjust the downstream steps to run based off our defined variables. Under the stored procedure settings, select the connection dropdown and then use dynamic content. Navigate to the variables section, which may need you to select the three dots on the right hand side, and click warehouseid, then 'OK' and do the same for the sql string. We then need to adjust two other inputs; first, click in the workspace ID and select use dynamic content and under system variables select Workspace ID (or just copy and paste the following '@pipeline().DataFactory'). Finally, type in the stored procedure name.
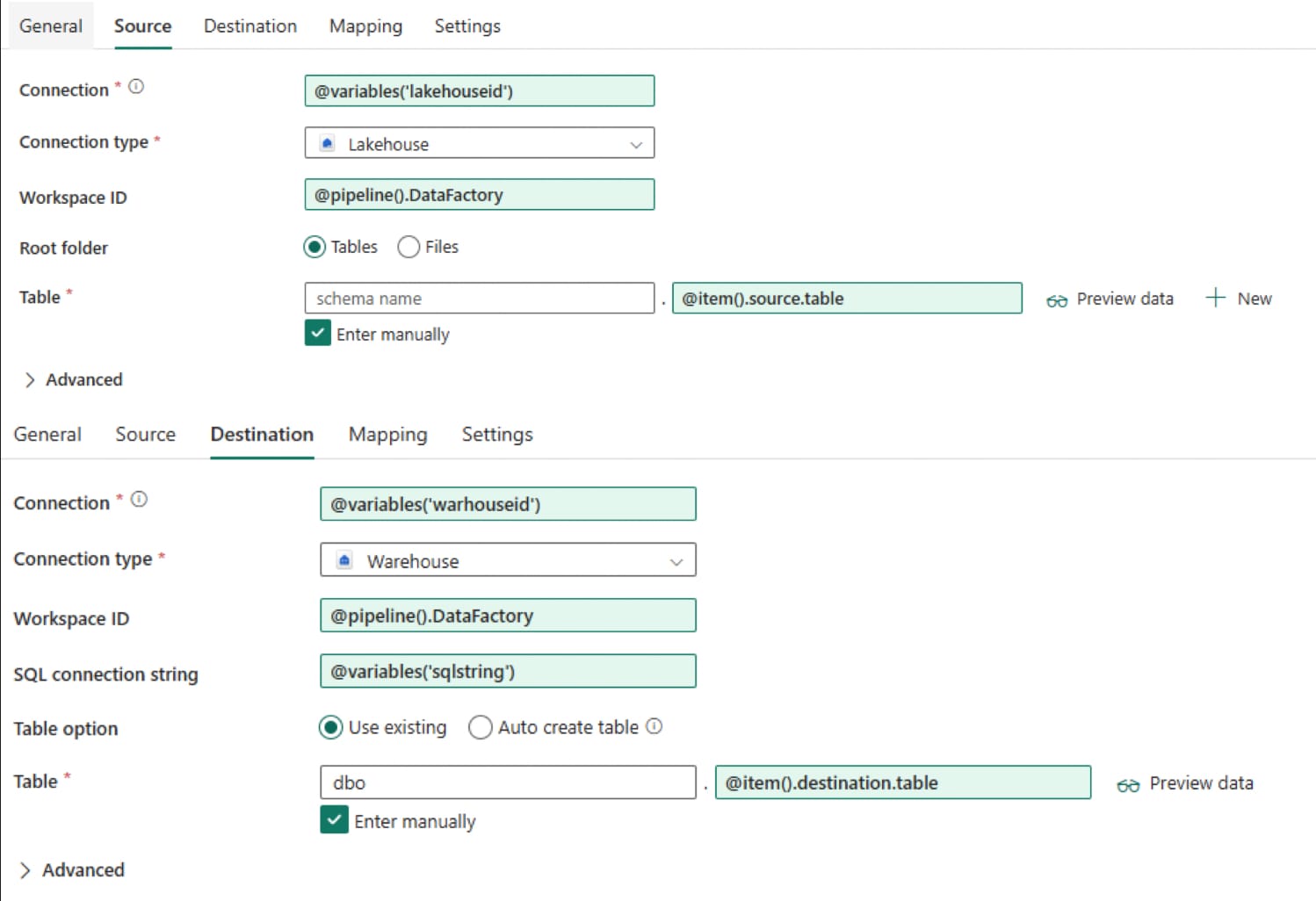
Now we need to configure the For each inner activity source and destination as below:
At this point, you can run the pipeline through and if all is configured properly, it should succeed. Usually the errors will give a good pointer where something has failed e.g. during testing I had an error where the table didn't exist because I'd cleared down my workspace without re-running ingest before testing this, but you can also check the monitor section for details and the input/output of each task in the pipeline to see where things are at.
Deploy to Another Workspace
Finally, to realise the benefit of this effort, it's worth deploying through a deployment pipeline. You'll see the connection on the lookup activity is still pointing to the dev workspace which is how I had this set up, but you can otherwise just click run and immediately populate your test workspace assuming the data is in place. If you followed part 1 of this blog, you will need to run the 'sourcepipeline' data pipeline first.

Considerations & Lessons Learned
- Originally, I tried using the connection (warehouse / lakehouse) names as that's how they appear in the drop down, but you need IDs here
- For the lakehouse, be careful to not use the SQL analytics endpoint, the lakehouse and SQL endpoint IDs aren't the same
- I would only follow this method where the input tables are static, or you're comfortable with either recreating the 'for each' copy assistant task when you need to update it or add another one (which would be messy). Though the JSON can be edited, you need to map every column source / sink
- Not truncating tables or dropping them before writing to a warehouse will populate with records twice
- This was done for testing, but in practice I would only be utilising the lakehouse and warehouse if the data was transformed between each so this pattern definitely needs updated before any production use, it's just a proof of concept
- I extended this by also adding a parameter that was static for the connection to the environment variables table. I would recommend doing so, but this blog felt a little on the long side already!