Microsoft Fabric Workspace Structure and Medallion Architecture Recommendations
Intro & Context
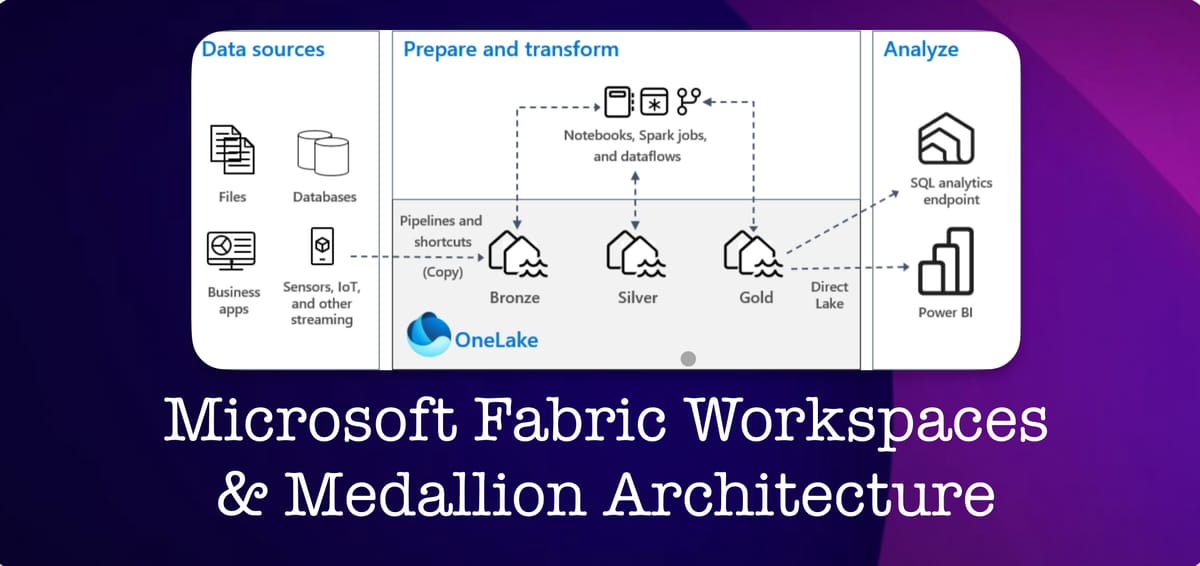
I’ll start by saying that I won’t be discussing the merits of the medallion architecture nor the discussion around building a literal medallion vs. Structuring against the requirements for your domain, and using medallion as a conceptual talking point, in any great detail as part of this blog (but I think this is a good video talking through the latter). We will just assume you’re following the guidance Microsoft publish describing the usual bronze, silver, and gold zones or layers.
I’ve seen a number of conversations online, namely on Fabric community blogs, Reddit, and Stackoverflow that primarily focus on the question of whether implementing the medallion architecture means we should have one workspace per domain (e.g. sales, HR data) that covers all layers or a workspace per layer (bronze, silver, gold) per domain. While these threads often end up with a single answer, I don’t think there is a single right answer, and I also think there is some nuance missed in this conversation. So what I’m going to cover here is some guidance around what the implications are around Fabric workspace structure as well as recommendations for a starting point. It’s also worth noting that this focuses primarily on lakehouse implementation.
Key Design Implications
Before sharing any recommendations, I want to get the “it depends” out of the way early. The “right” answer will always depend on the context of the environment and domain(s) in which you’re operating.
This is just a starting point and a way to break down some key decision areas. It’s worth noting there are lots of good resources and examples of people sharing online around their experiences, but the reason this blog exists is because I have seen these more often than not represent the most straightforward examples (single source systems or 1-2 user profiles) where following Microsoft’s demos learn materials is enough. As far as considering the implications of your workspace structure in Microsoft Fabric, I would suggest key areas include:
- Administration & Governance (who’s responsible for what, user personas)
- Security and Access Control (data sensitivity requirements, principle of least privilege)
- Data Quality checks, consistency, and lineage
- Capacity (SKU) features and requirements (F64-only features, isolating workloads)
- Users and skillsets
- Version control & elevation processes (naming conventions, keeping layers in sync)
Potential High Level Options
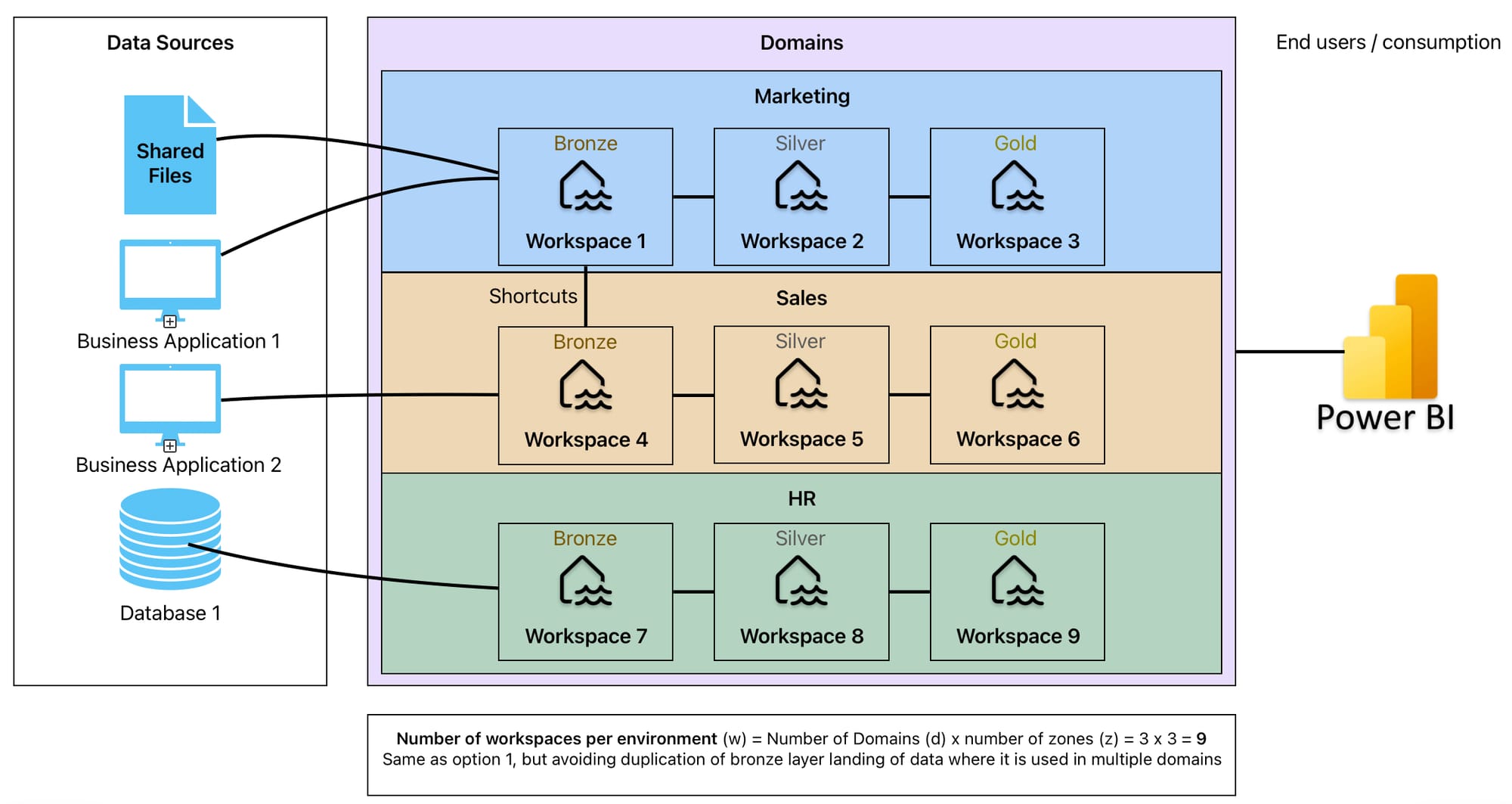
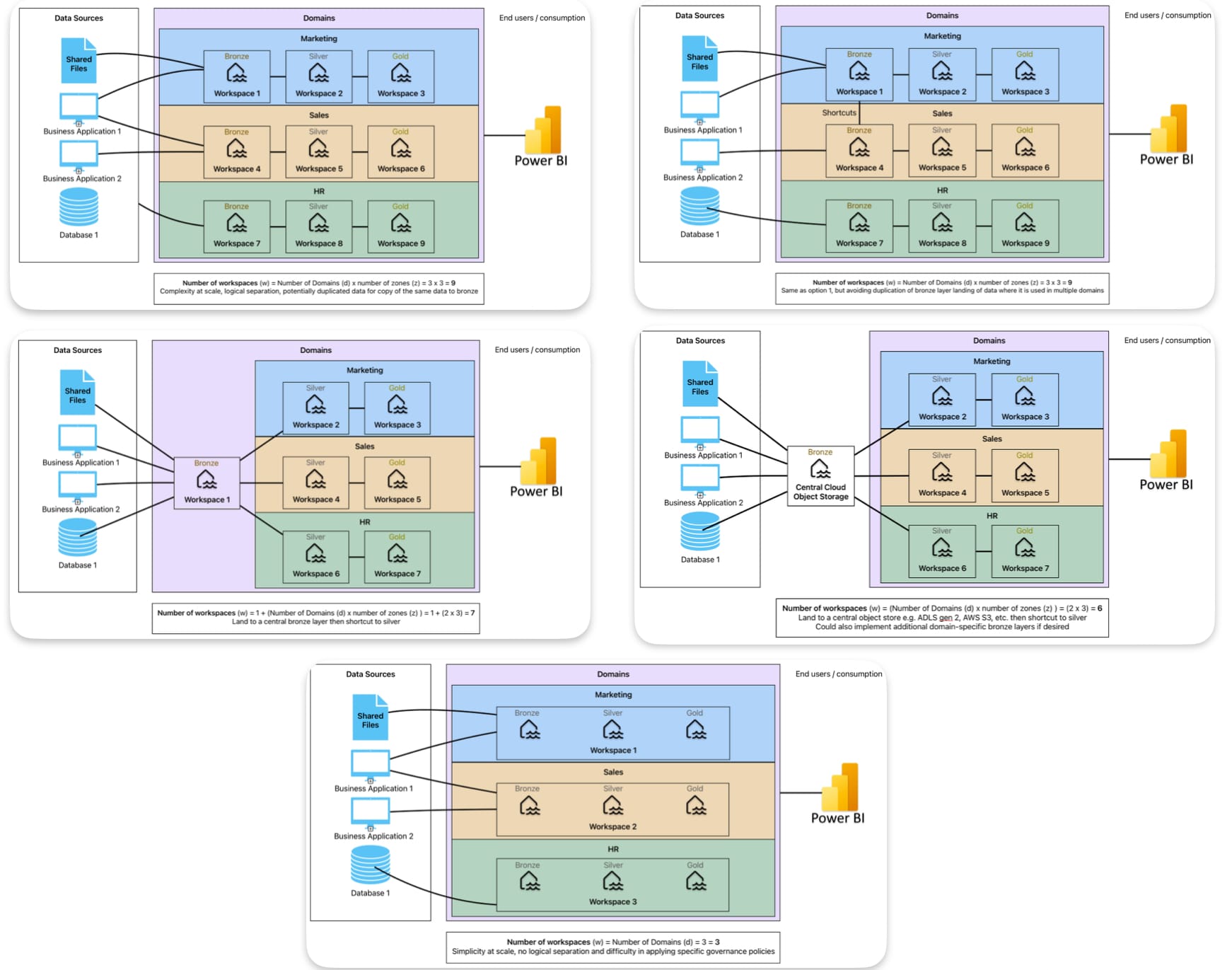
- 1 workspace per layer per domain. This is recommended by Microsoft (see “Deployment Model”) as it provides more control and governance. However, it does mean the number of workspaces can grow very quickly, and operational management (i.e. who owns the pipelines, data contracts, lineage from the source systems) needs to be carefully considered
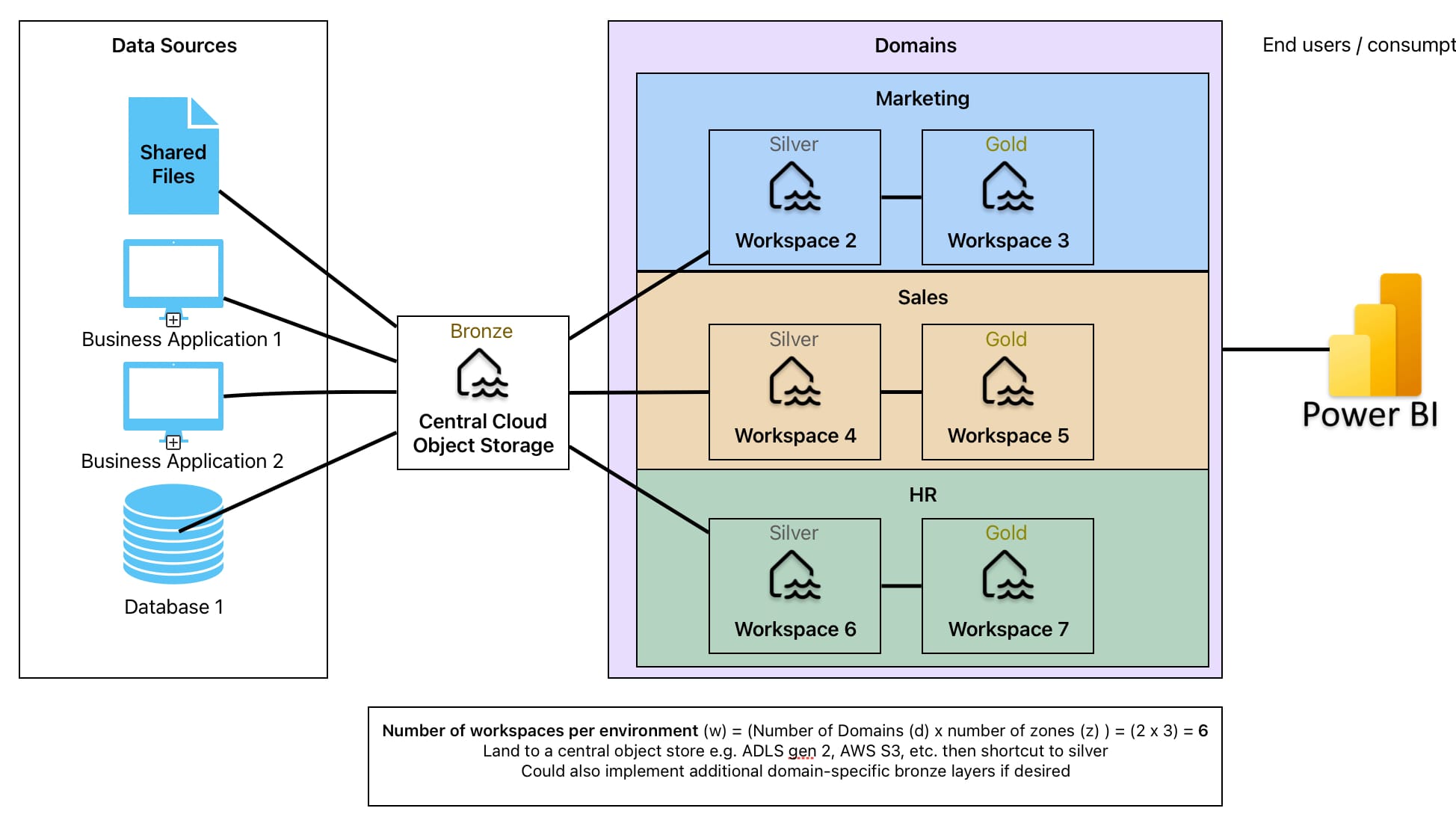
- 1 landing zone or bronze workspace then 1 workspace per domain for silver and gold layers. This could slightly reduce the number of workspaces by simply landing raw data in one place centrally but still maintaining separation in governance / management
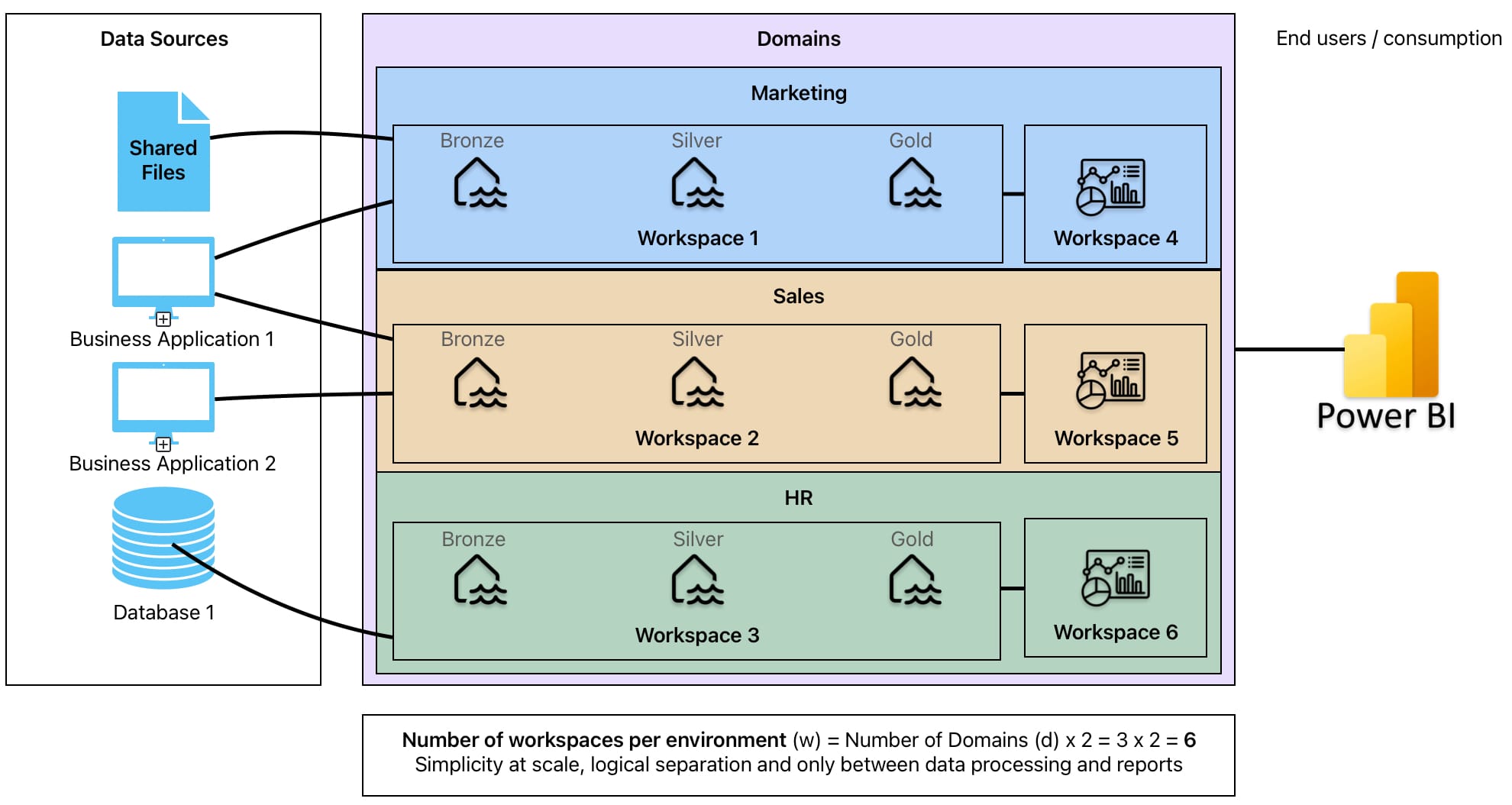
- One workspace per domain covering all layers. Though this is against the suggestion in Microsoft documentation, it is the most straightforward option, and for simple use cases where there are no specific constraints around governance and access, or where users will be operating across all layers, this could still be suitable
There’s also an additional decision point in terms of the approach to implementing the above for managing your bronze or raw data layer:
- A) Duplicate data - where multiple domains use the same data, simply duplicate the pipelines and data in each domain. I think this is mostly a case of ownership or stewardship and your preferred operating model given the cost of storage is relatively low
- B) Land data in a single bronze layer only, then use shortcuts - though the aim would be to utilise shortcuts to pull in data where possible, here I am specifically talking about agreeing that where raw data is used in multiple domains, you could land it in one bronze layer (say domain 1) then shortcut access to that in subsequent domains (domain 2, 3, etc.) to avoid duplication
- C) Use Cloud object storage for Bronze rather than Fabric Workspaces - this is an interesting one, and I think it only really applies if you plan to go with the core option 2 where you’re looking to have a centralised bronze layer. In this case you could do it in a Fabric workspace, or you could have a bronze layer cloud object store (ADLS gen2, s3, Google Cloud Storage, etc.). I think the only potential reason to consider this is to manage granular permissions for the data store outside of Fabric. In real terms, I would rule this out completely and instead consider (B)
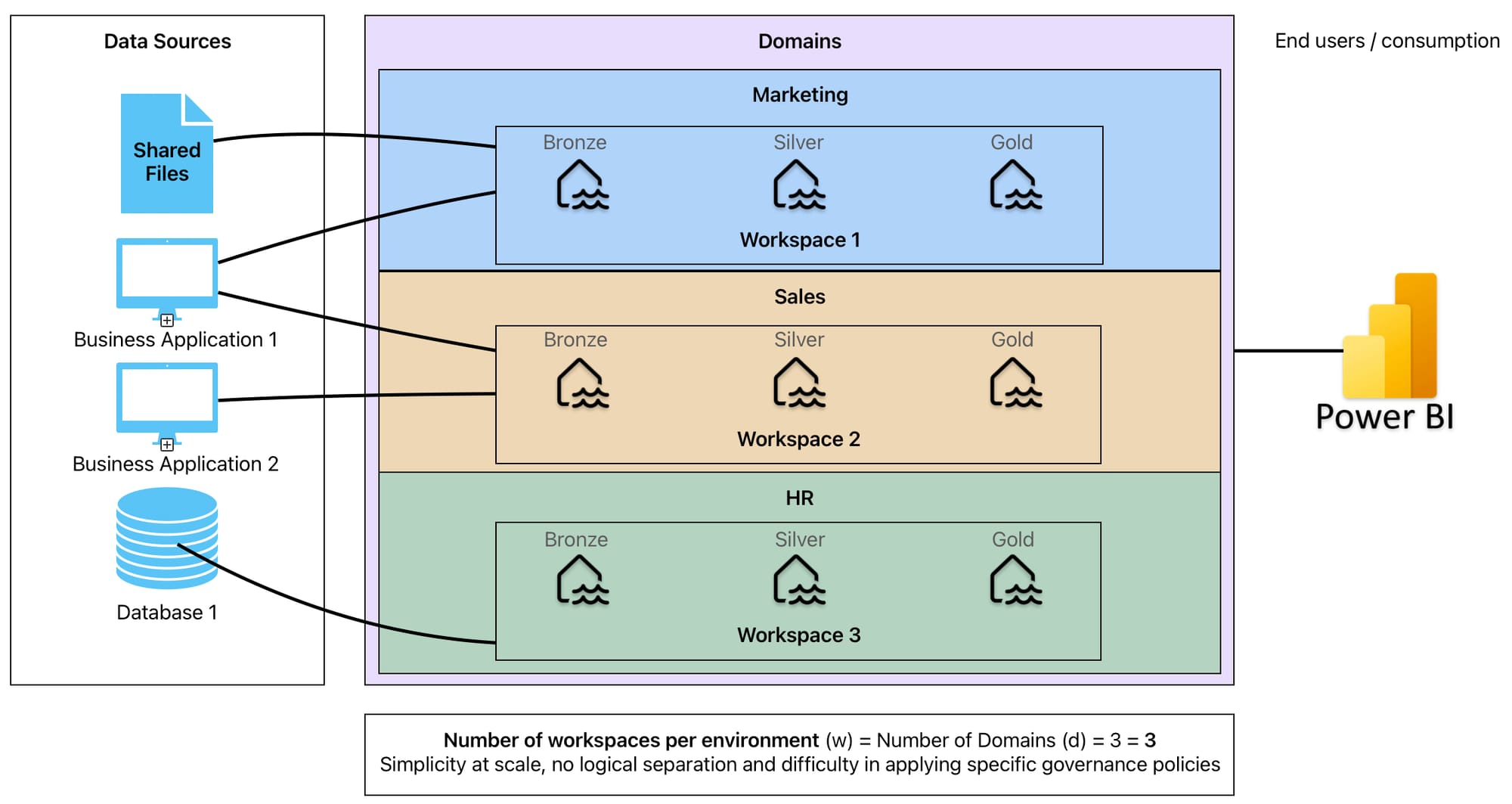
With the above in mind, you see how there are a number of approaches or options where the potential number of workspaces could be as large as the number of domains (d) multiplied by both the number of layers (3) and number of environments (e), and as small as the number of domains multiplied by the number of environments (d x 9 or d x 3 for dev, test, and prod environment structure). In the number of workspaces for each image, note that each would need to be multiplied by the number of environments (usually at least 3).
It’s also worth noting, the above list isn’t exhaustive. There are other options such as considering a monolithic (one workspace for all layers) approach for some federated teams, but segregated workspaces for centrally managed data, or using monolithic for medallion layers as in option 3 (think, platform or data workspace) and a separate workspace for reporting. This is all about targeting a starting point.
Sample Scenario
You might start to see why straightforward examples where an individual is setting up their Fabric workspace(s) covering use of data required for a single domain or team with limited risk of duplication and clear requirements around access controls results in an obvious structure. However, what does this mean when we begin to scale this across multiple domains in an organisation and a larger number of Fabric users?
For the purpose of considering any options, I’m going to make some assumptions for a sample scenario. We’re going to consider a fictional organisation that is rolling out Fabric across 3 domains initially; Sales, Marketing, and HR. Sales and Marketing will utilise at least one of the same source datasets, and there are no clear security or access controls between layers, but administration and governance must be segregated by domain. The organisation must keep separation between prod and non-prod workloads, and there will be dev, test, and prod environments.
In the sample scenario, there are a number of options, but we could recommend, for example:
- For each domain, utilise a workspace per environment (dev/test/prod)
- For each domain, utilise a single workspace consolidating medallion layers (bronze / raw to gold / ready for analytical use)
While this doesn’t seem unreasonable, I will admit that it’s not particularly realistic. In most cases, I would expect here to be a preference to have better governance and control around access to raw (bronze) data. In that case, while much of the above is accurate, I would expect the last point to be fundamentally different. Rather than moving to the other end of the spectrum creating individual workspaces for all layers, domains, and environments, a real-world example I worked through previously that was reasonably similar to the description above went with a single bronze layer landing zone (option 2B).
Recommendations
- There isn’t a single “right” answer here, so discussing the trade offs will only get you so far. I would suggest picking your best or clearest use case(s), reviewing your high level requirements, and build to a proposed or agreed approach then look to figure out if certain issues need addressed
- In general, I would recommend using shortcuts to minimise data duplication both across source storage and Fabric and across Fabric workspaces (described in option B). I really think it’s the best way to operate
- Start by testing the assumption that it makes sense to use one workspace covering all layers of the medallion (option 3). While I think this will only make sense in practice with some adjustment (e.g. splitting data and reporting), and Microsoft recommend a workspace per layer, this is the biggest influencing factor in terms of affecting administration at scale
- If you need to segregate medallion layers into individual workspace, I would propose starting with option 1 (B)
- Where possible, utilise different capacities for each environment, or at least for production environments to make sure production workloads aren’t affected by dev or test jobs. Though not specifically a recommendation related to workspaces, this has come up in any scoping I’ve been part of with Fabric capacity planning to date - in the sample scenario, that would mean two separate capacities, one for dev and test environments and one for prod to separate workloads, compromising between flexibility and management overhead. This would result in the number of workspaces being 3 times the number of domains rather than 9 times. This may change if there is more flexible workload management in future Fabric updates, and smoothing will help those running a single capacity, but it’s not currently possible to isolate workloads without multiple capacities
- There are also a couple of item level recommendations I would consider:
- Semantic models should primarily be implemented in the Gold layer - these are really to facilitate end use of modelled data. Adding semantic models in all layers could just add to the complexity of your Fabric estate
- It’s likely that the design pattern of utilising Lakehouses only or Warehouses only (only meaning from bronze to gold) will be common. However, it’s worth considering the different permutations against your needs. In my experience, a good starting point is using lakehouses for bronze and silver, and warehouses in gold (see here for some key differences)
- If you use a warehouse in the gold layer, look to utilise tables where possible and avoid views. Views will disable Directlake (or, rather, cause fallback behaviour) resulting in poorer performance
What Next?
I appreciate this has been focused on creating the starting point and I just wanted to add som personal opinions for how I’ve seen this work effectively. First of all, I think the decision around environment setup is more has a bigger effect than the trade off between a higher or lower number of workspaces. What I mean by that is that without having environments separated by a workspace boundary, utilising deployment pipelines and version control are either difficult or impossible, so it’s crucial to have different workspaces per environment.
Next, I believe that the key driver for creating workspaces per medallion layer is around data governance and access controls. For me, the most logical way to balance that with the administration overhead is to use option 3 the monolithic approach, and add additional “reporting” workspaces for each to allow governance and access control management between accessing source data and consuming reports without having a massive number of workspaces to manage.