Minimising Spark Startup Duration in Microsoft Fabric

Context
Often with cloud services, consumption equals cost. Microsoft fabric isn’t much different, though there is some nuance with the billing model in that, in some cases, increasing consumption by 20-30% could double the cost due to the need to move to a bigger and in other cases you might have the overhead and see no cost increase. I‘m keen not to get into the depths of SKUs and CU consumption here, but, at the most basic level for spark notebooks, time / duration has a direct correlation with cost and it makes sense generally to look for opportunities to minimise CU consumption.
In terms of where this becomes relevant in relation to spark startup times in Fabric, it’s worth noting that this duration counts as CU(s) consumption for scheduled notebooks, and also increases the duration of each pipeline.
I’ll start by sharing a couple of screenshots with session start times where high concurrency sessions and starter pools (details below) aren’t used. After running each half a dozen times, the start times were almost always over 2 minutes and up to 7 minutes with an average of around 3 minutes.
Environments
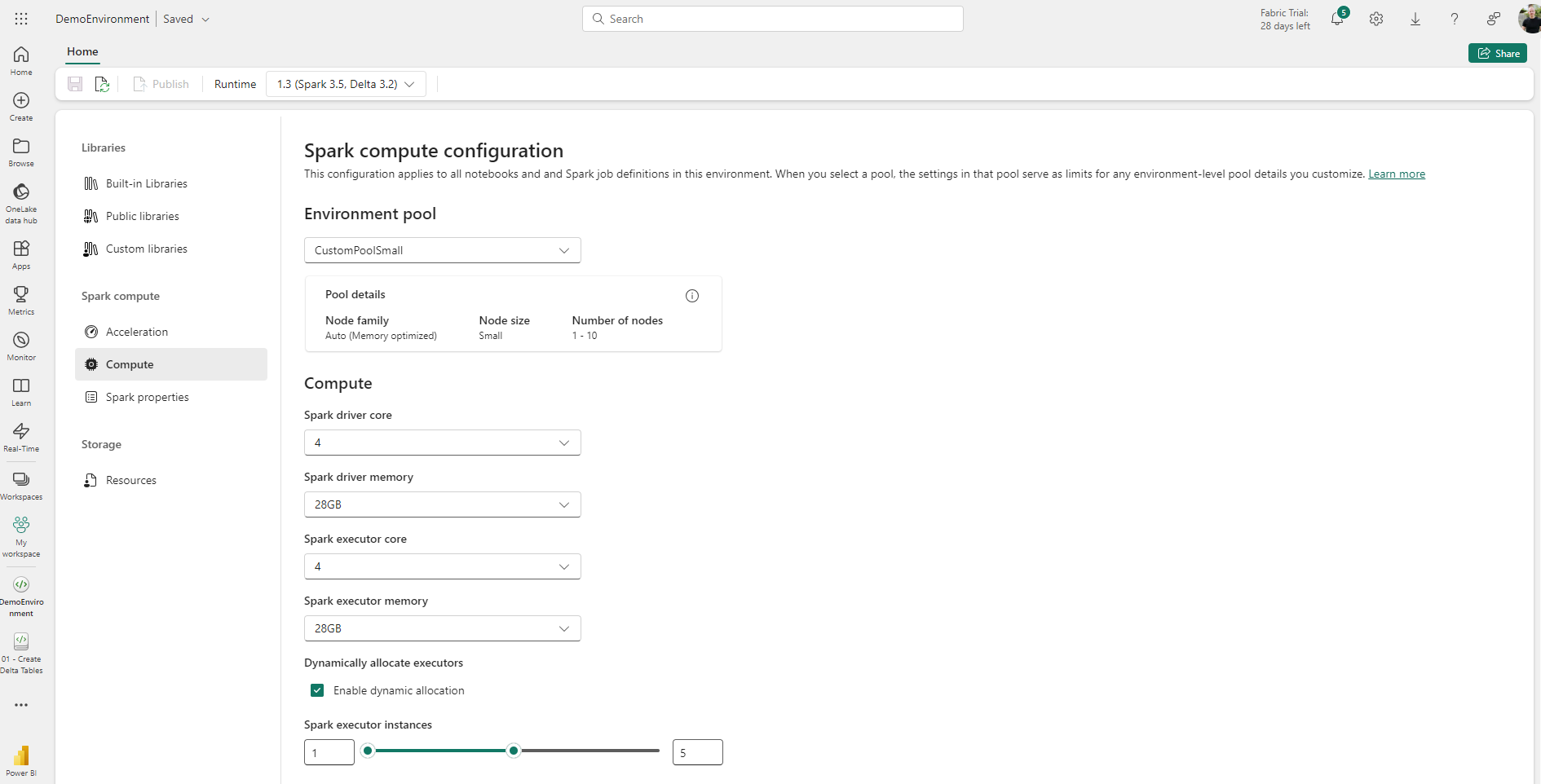
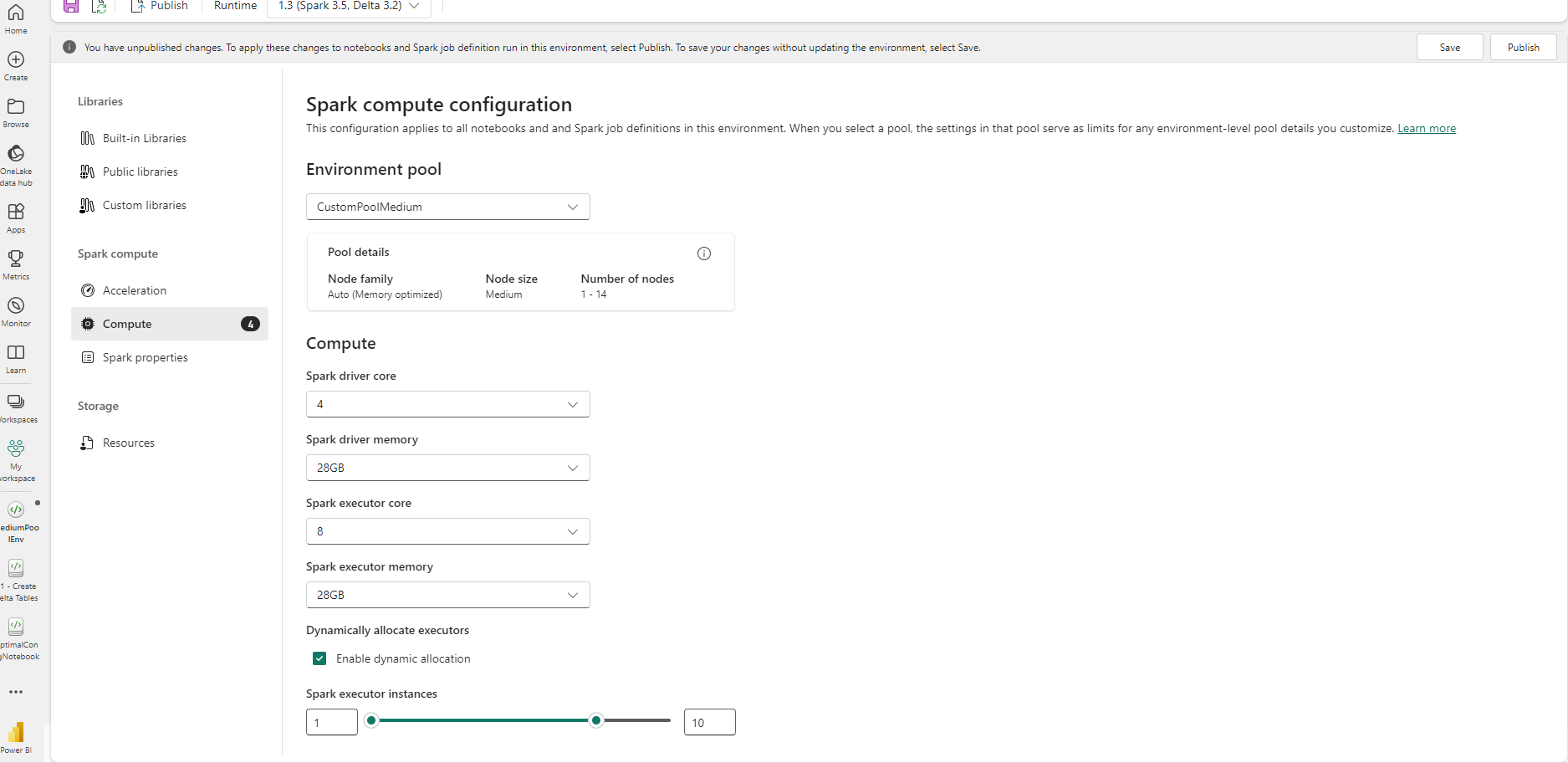
Before jumping in to a couple of recommendations and examples, I also wanted to comment briefly on Fabric environments. Environments can be used to consolidate and standardise hardware and software settings. The Microsoft documentation has more information on this. Up until running a series of testing for this blog I had mainly used environments for deploying custom python packages, but you’ll see a custom environment in some screenshots below (for the small node size) where I adapted environment settings to quickly enable changes in spark compute resources and apply them consistently across sessions, without changing the workspace default, for testing the high concurrency sessions with specific compute resources.
Basic Testing
Having run sessions without utilising high concurrency or starter pools for a range of environments, the results are outlined below;
- Small node size, memory optimised, 1-10 nodes - 2 minutes 42 seconds
- Medium node size - this one was interesting. If you create a custom pool with similar settings to the default starter pool, startup can be around 10 seconds, but minor adjustments to the pool, namely adjusting number of drivers or executors, or memory from 56GB to 28GB, saw this jump to 7 minutes 7 seconds
- Large node size, memory optimised, 1-6 nodes - 2 minutes 17 seconds
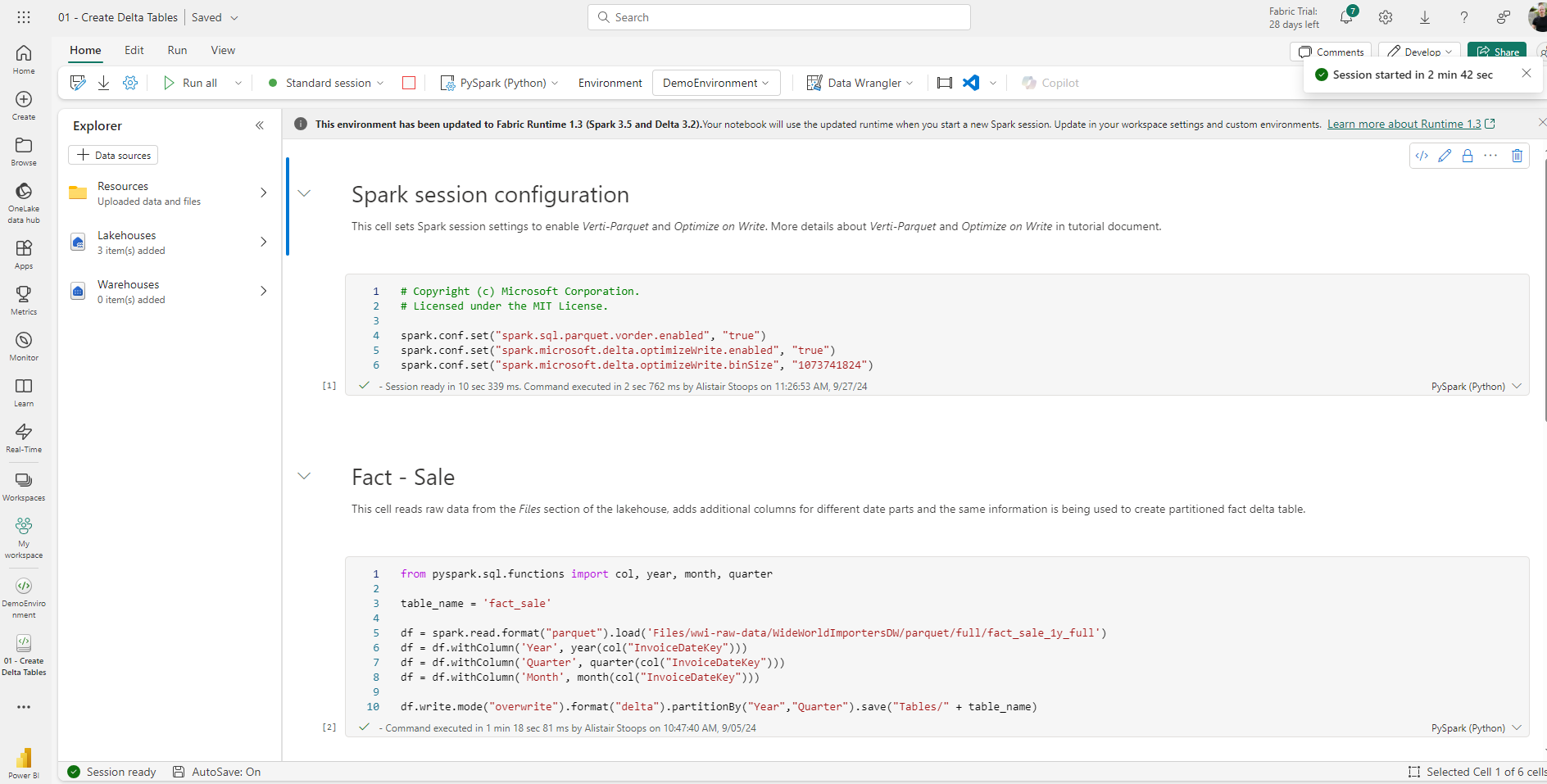
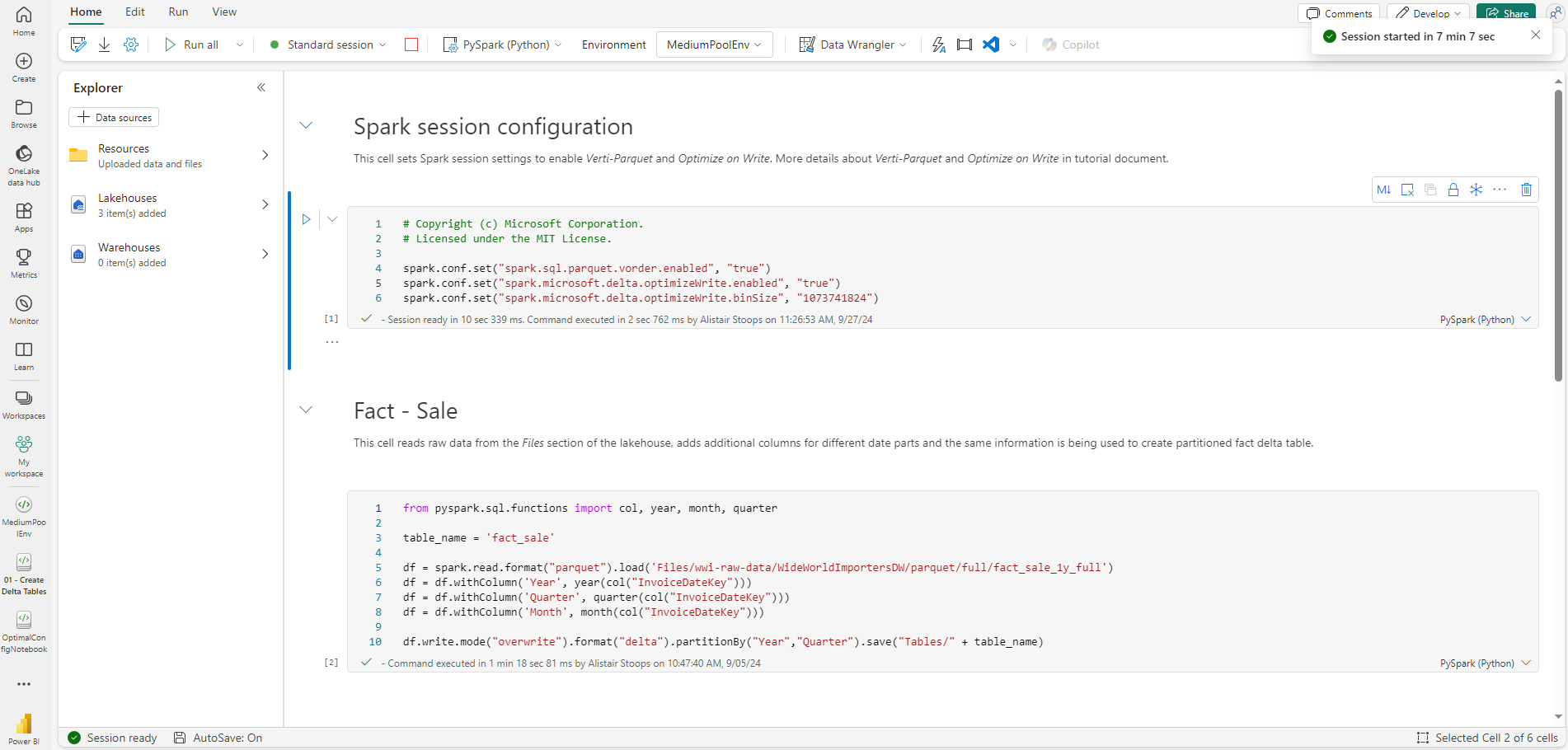
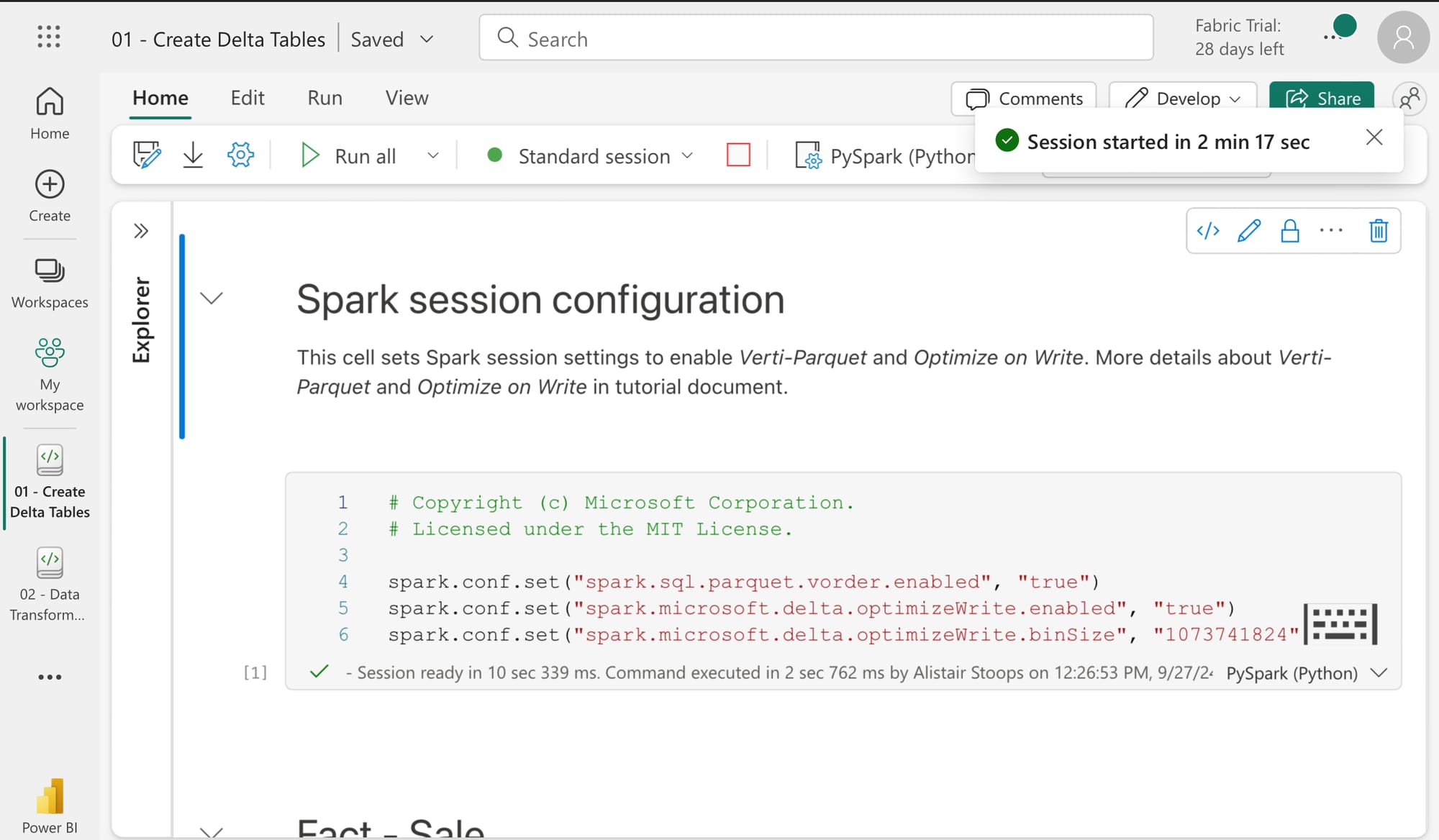
High Concurrency
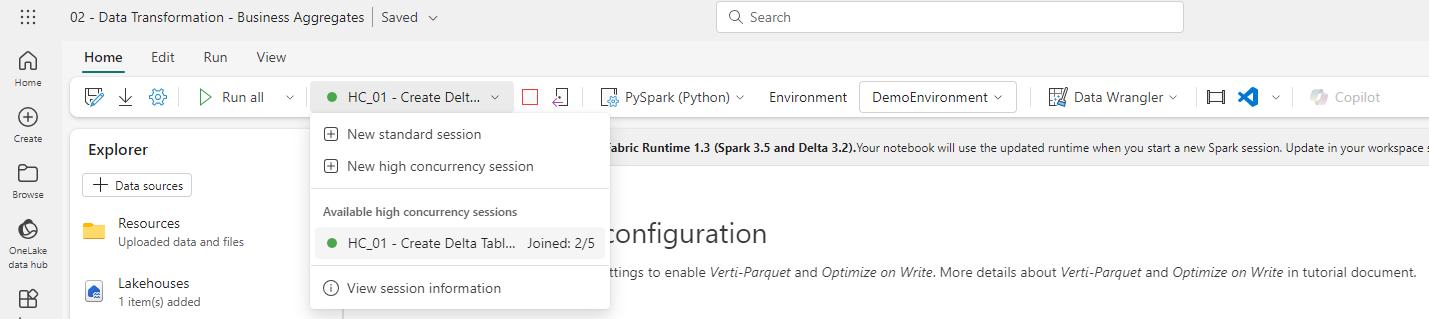
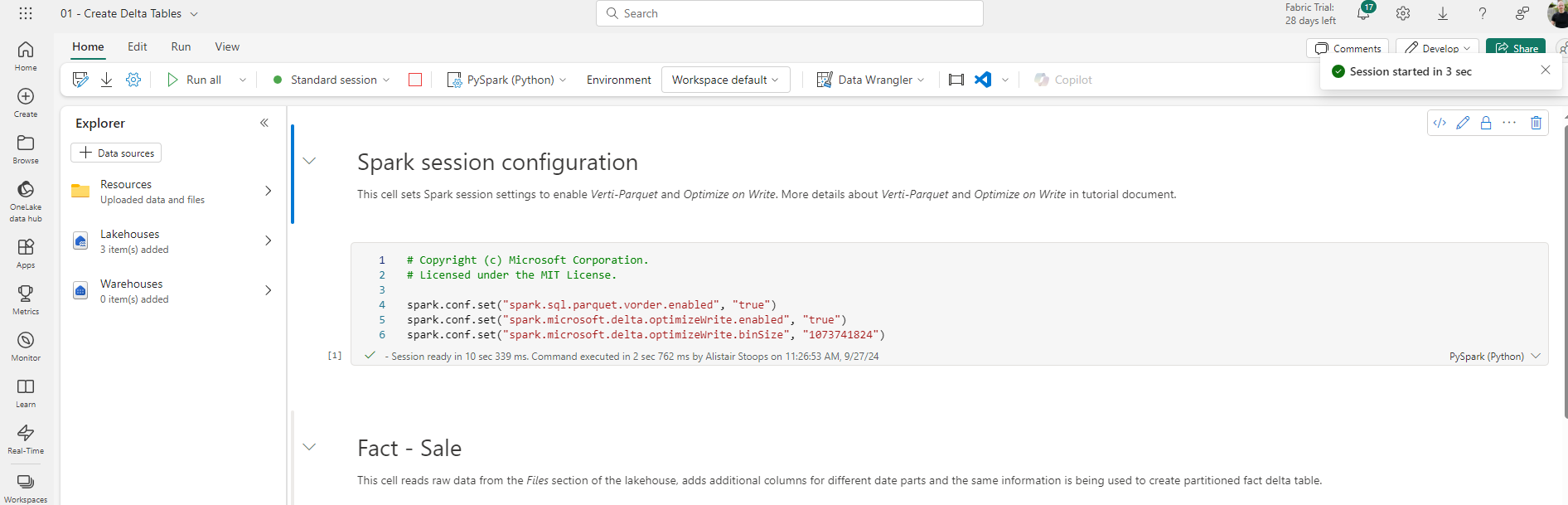
High concurrency mode in Fabric enables users to share spark sessions for up to 5 concurrent sessions. Though there are some considerations, namely around the requirement for utilising the same spark compute properties, the Microsoft documentation suggests a 36 times faster session start for custom pools. In my experience, the actual start time was even quicker than suggested, almost instantaneous, compared to around 3 minutes, and across 3 tests this ranged from 55 times faster to almost 90. That said, it’s also worth noting that first high concurrency session start was often slightly longer than starting a standard session where it was more like 3 minutes than 2.5.
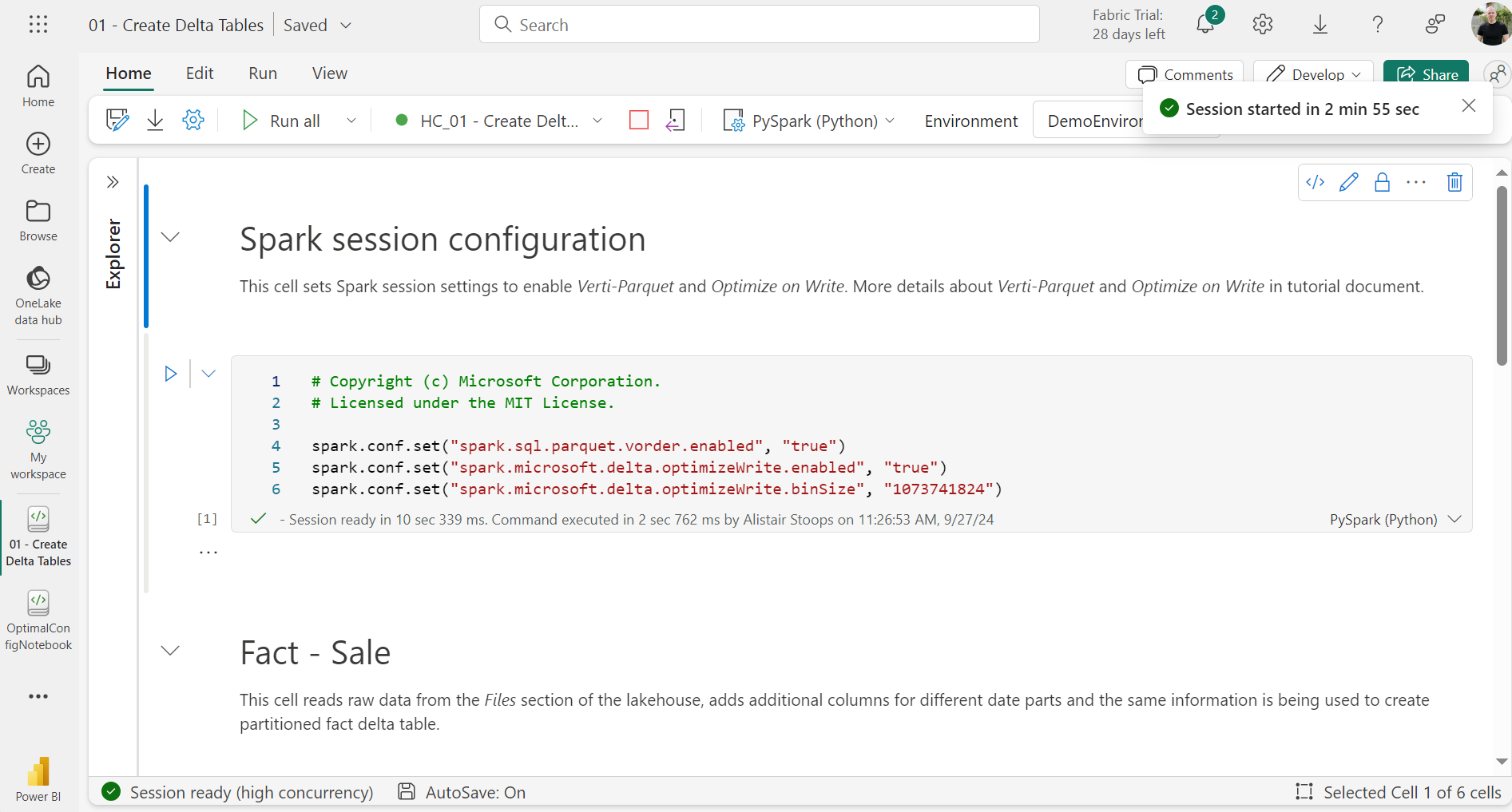
In all node size variations, the startup times for further high concurrency sessions was either 2 or 3 seconds. The images below were taken for the demo environment outlined above (small node size).
Starter Pools
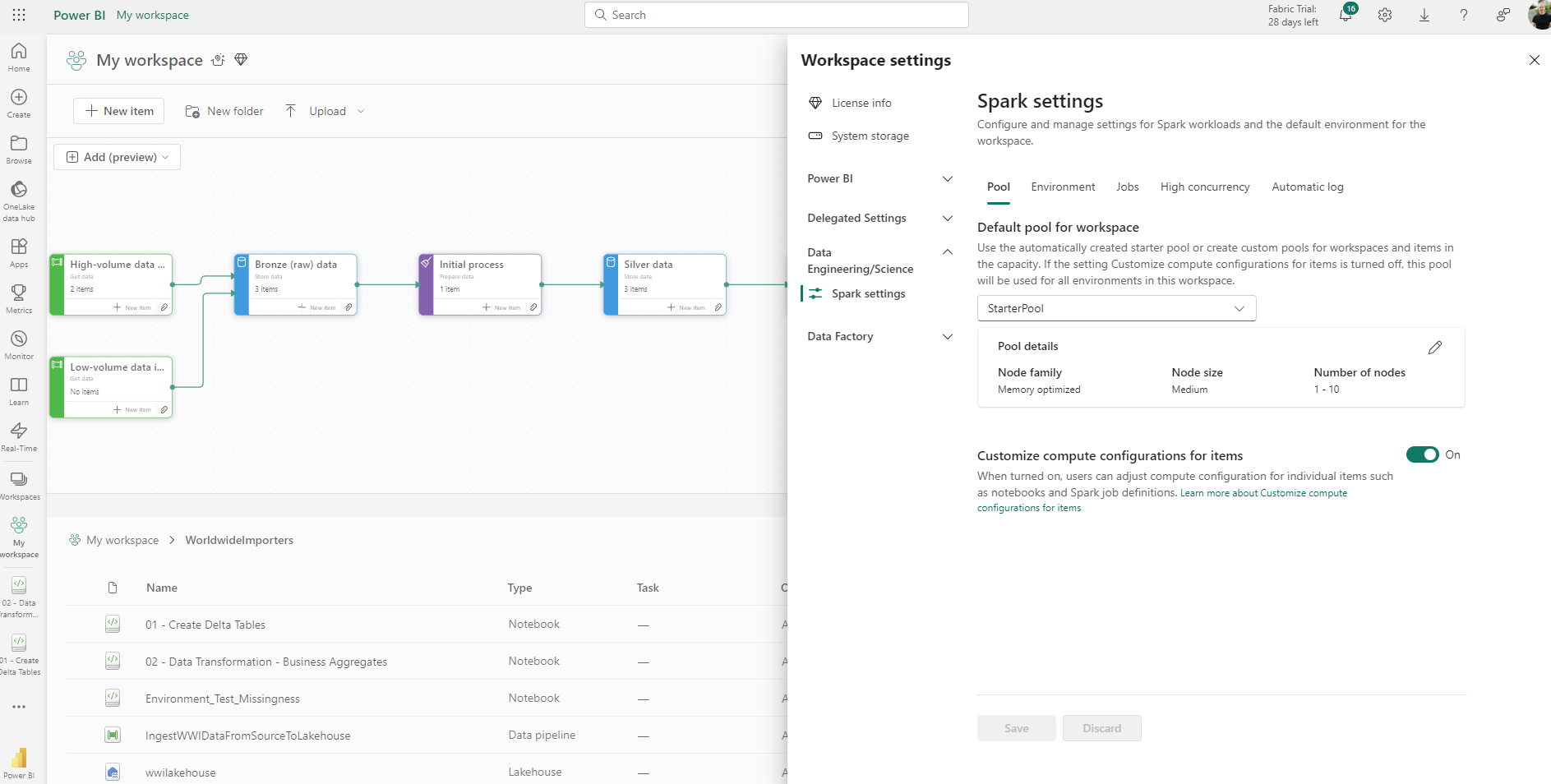
Fabric Starter Pools are always-on spark clusters that are ready to use with almost no startup time. You can still configure starter pools for autoscaling and dynamic allocation, but node family and size are locked to medium and memory optimised. In my experience, startup time was anywhere from 3 to 8 seconds.
Closing Thoughts
In short, where you’re comfortable with existing configurations and consumption, or no custom pools are required, look to utilise starter pools. Where custom pools are required due to tailoring requirements around node size or family, and multiple developers are working in parallel, aim to use high concurrency sessions.